Robust Policy Optimization (RPO)
Overview
RPO leverages a method of perturbing the distribution representing actions. The goal is to encourage high-entropy actions and provide a better representation of the action space. The method consists of a simple modification on top of the objective of the PPO algorithm. In the RPO algorithm, the mean of the action distribution is perturbed using a random number drawn from a Uniform distribution.
Original paper:
Implemented Variants
| Variants Implemented | Description |
|---|---|
rpo_continuous_action.py, docs |
For classic control tasks like Gym Pendulum-v1, and dm_control. |
Below are our single-file implementations of RPO:
rpo_continuous_action.py
rpo_continuous_action.py works with Gym (Gymnasium), dm_control, Mujoco environments with continuous action and vector observations.
The rpo_continuous_action.py has the following features (similar to ppo_continuous_action.py):
- For continuous action space. Also implemented Mujoco-specific code-level optimizations
- Works with the
Boxobservation space of low-level features - Works with the
Box(continuous) action space - adding experimental support for Gymnasium
- 🧪 support
dm_controlenvironments via Shimmy
Usage
# mujoco v4 environments
uv pip install ".[mujoco]"
python cleanrl/rpo_continuous_action.py --help
python cleanrl/rpo_continuous_action.py --env-id Walker2d-v4
# NOTE: we recommend using --rpo-alpha 0.01 for Ant Hopper InvertedDoublePendulum Reacher Pusher
python cleanrl/rpo_continuous_action.py --env-id Ant-v4 --rpo-alpha 0.01
# dm_control v4 environments
uv pip install ".[mujoco, dm_control]"
python cleanrl/rpo_continuous_action.py --env-id dm_control/cartpole-balance-v0
# BipedalWalker-v3 experiment (hack)
uv pip install .
uv pip install box2d-py==2.3.5
python cleanrl/rpo_continuous_action.py --env-id BipedalWalker-v3
# mujoco v4 environments
uv pip install ".[mujoco]"
python cleanrl/rpo_continuous_action.py --help
python cleanrl/rpo_continuous_action.py --env-id Hopper-v4
# NOTE: we recommend using --rpo-alpha 0.01 for Ant Hopper InvertedDoublePendulum Reacher Pusher
python cleanrl/rpo_continuous_action.py --env-id Ant-v4 --rpo-alpha 0.01
# dm_control environments
uv pip install ".[mujoco, dm_control]"
python cleanrl/rpo_continuous_action.py --env-id dm_control/cartpole-balance-v0
# BipedalWalker-v3 experiment (hack)
uv pip install box2d-py==2.3.5
uv run python cleanrl/rpo_continuous_action.py --env-id BipedalWalker-v3
pip install -r requirements/requirements-mujoco.txt
python cleanrl/rpo_continuous_action.py --help
python cleanrl/rpo_continuous_action.py --env-id Hopper-v4
# NOTE: we recommend using --rpo-alpha 0.01 for Ant Hopper InvertedDoublePendulum Reacher Pusher
python cleanrl/rpo_continuous_action.py --env-id Ant-v4 --rpo-alpha 0.01
pip install -r requirements/requirements-dm_control.txt
python cleanrl/rpo_continuous_action.py --env-id dm_control/cartpole-balance-v0
pip install box2d-py==2.3.5
python cleanrl/rpo_continuous_action.py --env-id BipedalWalker-v3
Explanation of the logged metrics
See related docs for ppo.py.
Implementation details
rpo_continuous_action.py has the same implementation details as ppo_continuous_action.py (see related docs) but with a few lines of code differences.
class Agent(nn.Module):
def __init__(self, envs):
super().__init__()
self.critic = nn.Sequential(
layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 1), std=1.0),
)
self.actor_mean = nn.Sequential(
layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 64)),
nn.Tanh(),
layer_init(nn.Linear(64, np.prod(envs.single_action_space.shape)), std=0.01),
)
self.actor_logstd = nn.Parameter(torch.zeros(1, np.prod(envs.single_action_space.shape)))
def get_value(self, x):
return self.critic(x)
def get_action_and_value(self, x, action=None):
action_mean = self.actor_mean(x)
action_logstd = self.actor_logstd.expand_as(action_mean)
action_std = torch.exp(action_logstd)
probs = Normal(action_mean, action_std)
if action is None:
action = probs.sample()
else: # new to RPO
# sample again to add stochasticity, for the policy update
z = torch.FloatTensor(action_mean.shape).uniform_(-self.rpo_alpha, self.rpo_alpha)
action_mean = action_mean + z
probs = Normal(action_mean, action_std)
Note
RPO usages the same PPO-specific hyperparameters. In benchmarking results, we run both algorithms for 8M timesteps.
RPO has one additional hyperparameter, rpo_alpha, which determines the amount of random perturbation on the action mean.
We set a default value of rpo_alpha=0.5 at which RPO is strictly equal to or better than the default PPO in 93% of environments tested (all 48/48 dm_control, 2/2 Gym, 7/11 mujoco_v4. Total 57 out of 61 environments tested.).
With finetuning rpo_alpha=0.01 on four mujoco environments, namely, Ant, InvertedDoublePendulum, Reacher, and Pusher, RPO is strictly equal to or better than the default PPO in all tested environments.
Experiment results
To run benchmark experiments, see benchmark/rpo.sh. Specifically, execute the following command:
Result tables, learning curves
Results on all dm_control environments. The PPO and RPO run for 8M timesteps, and results are computed over 10 random seeds.
| ppo_continuous_action_8M ({'tag': ['v1.0.0-13-gcbd83f6']}) | rpo_continuous_action ({'tag': ['pr-331']}) | |
|---|---|---|
| dm_control/acrobot-swingup-v0 | 26.87 ± 7.93 | 42.97 ± 2.71 |
| dm_control/acrobot-swingup_sparse-v0 | 1.70 ± 0.88 | 3.31 ± 0.84 |
| dm_control/ball_in_cup-catch-v0 | 935.26 ± 12.57 | 939.75 ± 10.18 |
| dm_control/cartpole-balance-v0 | 790.36 ± 17.64 | 795.12 ± 10.49 |
| dm_control/cartpole-balance_sparse-v0 | 986.04 ± 9.93 | 988.56 ± 4.28 |
| dm_control/cartpole-swingup-v0 | 590.21 ± 16.72 | 613.46 ± 10.91 |
| dm_control/cartpole-swingup_sparse-v0 | 240.14 ± 299.93 | 525.49 ± 185.96 |
| dm_control/cartpole-two_poles-v0 | 216.31 ± 4.03 | 218.31 ± 7.30 |
| dm_control/cartpole-three_poles-v0 | 160.03 ± 2.52 | 159.97 ± 2.28 |
| dm_control/cheetah-run-v0 | 472.14 ± 99.62 | 565.51 ± 58.03 |
| dm_control/dog-stand-v0 | 332.06 ± 23.66 | 501.22 ± 131.98 |
| dm_control/dog-walk-v0 | 124.92 ± 23.13 | 166.39 ± 44.65 |
| dm_control/dog-trot-v0 | 79.89 ± 12.30 | 115.39 ± 29.68 |
| dm_control/dog-run-v0 | 69.07 ± 8.17 | 104.27 ± 24.44 |
| dm_control/dog-fetch-v0 | 28.34 ± 4.87 | 43.58 ± 6.88 |
| dm_control/finger-spin-v0 | 630.06 ± 252.99 | 848.67 ± 25.21 |
| dm_control/finger-turn_easy-v0 | 237.76 ± 78.10 | 450.88 ± 133.54 |
| dm_control/finger-turn_hard-v0 | 83.76 ± 28.96 | 259.99 ± 144.83 |
| dm_control/fish-upright-v0 | 559.72 ± 65.79 | 803.21 ± 28.36 |
| dm_control/fish-swim-v0 | 80.42 ± 9.18 | 140.33 ± 49.10 |
| dm_control/hopper-stand-v0 | 3.26 ± 1.65 | 404.39 ± 198.17 |
| dm_control/hopper-hop-v0 | 6.48 ± 18.92 | 62.60 ± 87.29 |
| dm_control/humanoid-stand-v0 | 20.76 ± 29.35 | 140.43 ± 57.27 |
| dm_control/humanoid-walk-v0 | 8.92 ± 18.01 | 77.00 ± 53.00 |
| dm_control/humanoid-run-v0 | 5.44 ± 9.16 | 24.00 ± 19.54 |
| dm_control/humanoid-run_pure_state-v0 | 1.13 ± 0.11 | 3.24 ± 2.41 |
| dm_control/humanoid_CMU-stand-v0 | 4.64 ± 0.37 | 4.32 ± 0.33 |
| dm_control/humanoid_CMU-run-v0 | 0.88 ± 0.09 | 0.80 ± 0.09 |
| dm_control/manipulator-bring_ball-v0 | 0.42 ± 0.14 | 0.44 ± 0.23 |
| dm_control/manipulator-bring_peg-v0 | 0.95 ± 0.43 | 1.07 ± 1.01 |
| dm_control/manipulator-insert_ball-v0 | 41.24 ± 27.27 | 43.63 ± 12.77 |
| dm_control/manipulator-insert_peg-v0 | 40.72 ± 15.95 | 44.87 ± 26.55 |
| dm_control/pendulum-swingup-v0 | 472.19 ± 385.47 | 774.30 ± 21.03 |
| dm_control/point_mass-easy-v0 | 534.23 ± 264.35 | 653.73 ± 23.14 |
| dm_control/point_mass-hard-v0 | 129.75 ± 61.18 | 185.81 ± 36.25 |
| dm_control/quadruped-walk-v0 | 247.29 ± 90.48 | 602.64 ± 223.23 |
| dm_control/quadruped-run-v0 | 171.50 ± 37.90 | 367.98 ± 117.18 |
| dm_control/quadruped-escape-v0 | 23.11 ± 10.48 | 68.50 ± 27.81 |
| dm_control/quadruped-fetch-v0 | 183.71 ± 25.14 | 216.32 ± 17.44 |
| dm_control/reacher-easy-v0 | 773.01 ± 56.70 | 716.89 ± 50.07 |
| dm_control/reacher-hard-v0 | 637.84 ± 81.15 | 576.81 ± 48.25 |
| dm_control/stacker-stack_2-v0 | 58.02 ± 11.04 | 70.95 ± 16.84 |
| dm_control/stacker-stack_4-v0 | 73.84 ± 14.48 | 65.54 ± 18.06 |
| dm_control/swimmer-swimmer6-v0 | 164.22 ± 18.44 | 159.60 ± 39.52 |
| dm_control/swimmer-swimmer15-v0 | 161.02 ± 24.56 | 153.91 ± 28.08 |
| dm_control/walker-stand-v0 | 439.24 ± 210.22 | 734.74 ± 142.52 |
| dm_control/walker-walk-v0 | 305.74 ± 92.15 | 787.11 ± 125.97 |
| dm_control/walker-run-v0 | 128.18 ± 91.52 | 391.56 ± 119.75 |
Learning curves:
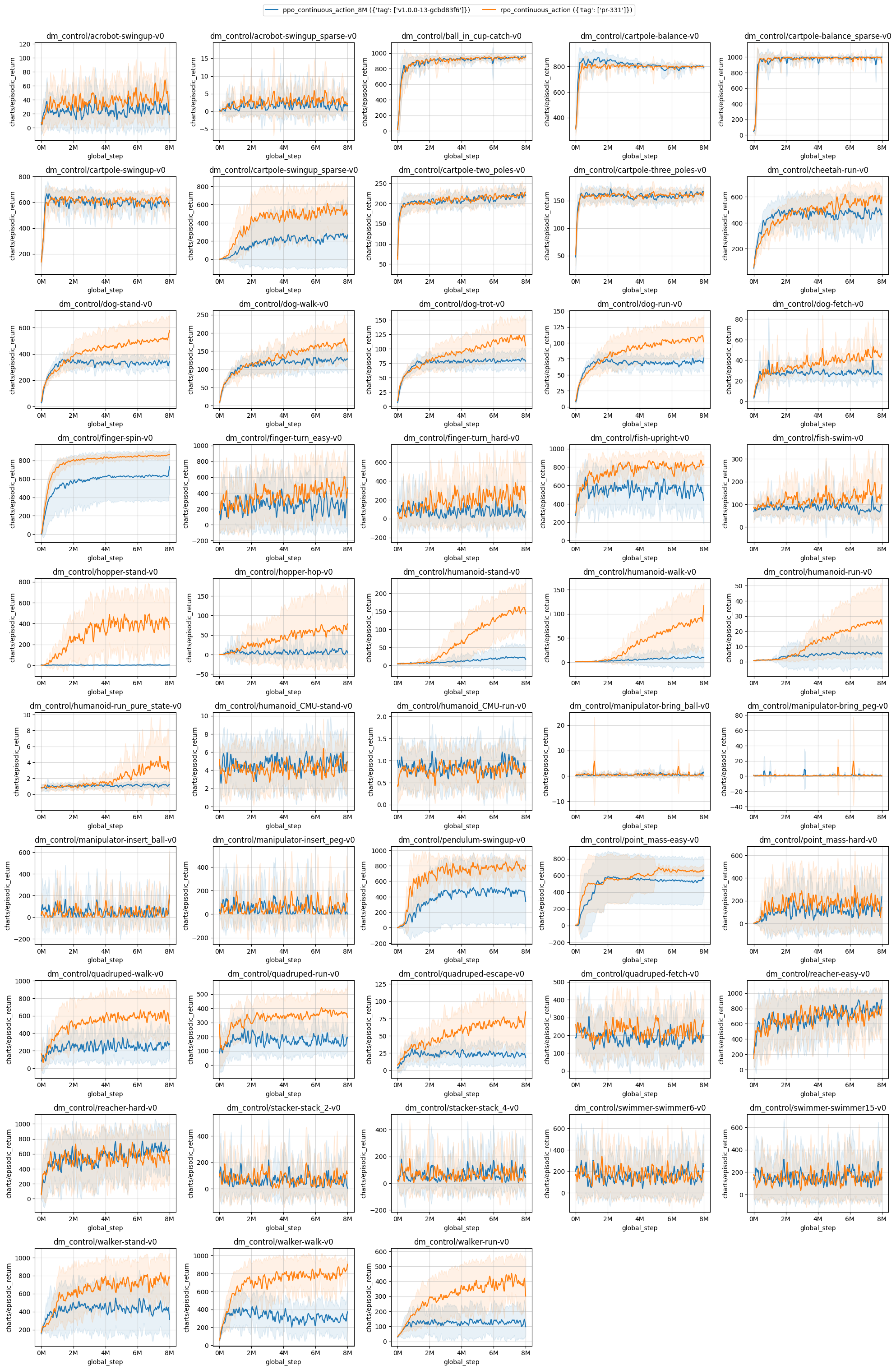
Tracked experiments:
| ppo_continuous_action_8M ({'tag': ['v1.0.0-13-gcbd83f6']}) | rpo_continuous_action ({'tag': ['pr-331']}) | |
|---|---|---|
| HumanoidStandup-v4 | 109325.87 ± 16161.71 | 150972.11 ± 6926.19 |
| Humanoid-v4 | 583.17 ± 27.88 | 799.44 ± 170.85 |
| InvertedPendulum-v4 | 888.83 ± 34.66 | 879.81 ± 35.52 |
| Walker2d-v4 | 2872.92 ± 690.53 | 3665.48 ± 278.61 |
Learning curves:
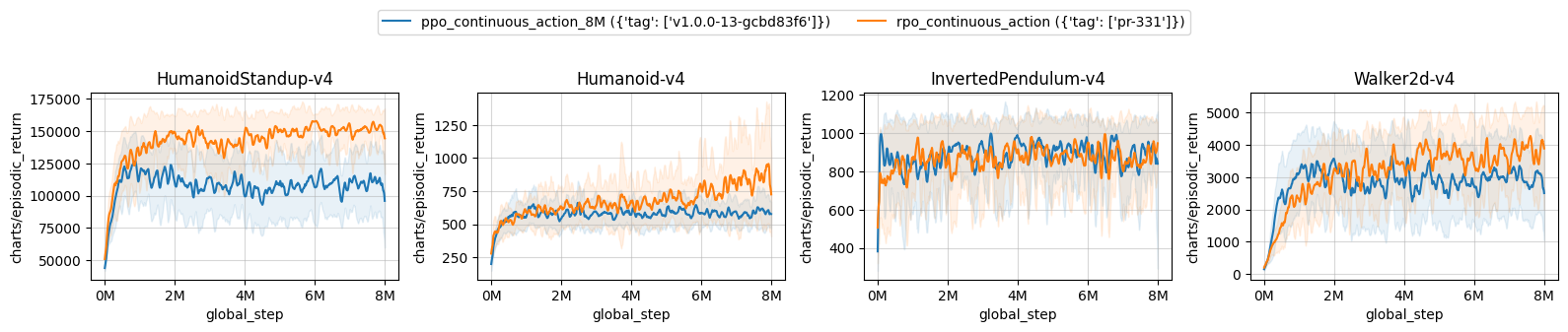
Tracked experiments:
The following environments require tuning of alpha (Algorithm 1, line 13, paper: https://arxiv.org/pdf/2212.07536.pdf). As described in the paper, this variable should be tuned for environments tested. A larger value means more randomness, whereas a smaller value indicates less randomness. Some mujoco environments require a smaller alpha=0.01 value to achieve a reasonable performance compared to alpha=0.5 for the rest of the environments. This version (alpha=0.01) of runs is indicated as rpo_continuous_action_alpha_0_01 in the table and learning curves.
| ppo_continuous_action_8M ({'tag': ['v1.0.0-13-gcbd83f6']}) | rpo_continuous_action_alpha_0_01 ({'tag': ['pr-331']}) | |
|---|---|---|
| Ant-v4 | 1824.17 ± 905.78 | 2702.91 ± 683.53 |
| HalfCheetah-v4 | 2637.19 ± 1068.49 | 2716.51 ± 1314.93 |
| Hopper-v4 | 2741.42 ± 269.11 | 2334.22 ± 441.89 |
| InvertedDoublePendulum-v4 | 5626.22 ± 289.23 | 5409.03 ± 318.68 |
| Reacher-v4 | -4.65 ± 0.96 | -3.93 ± 0.19 |
| Swimmer-v4 | 124.88 ± 22.24 | 129.97 ± 12.02 |
| Pusher-v4 | -30.35 ± 6.43 | -31.48 ± 9.83 |
Learning curves:
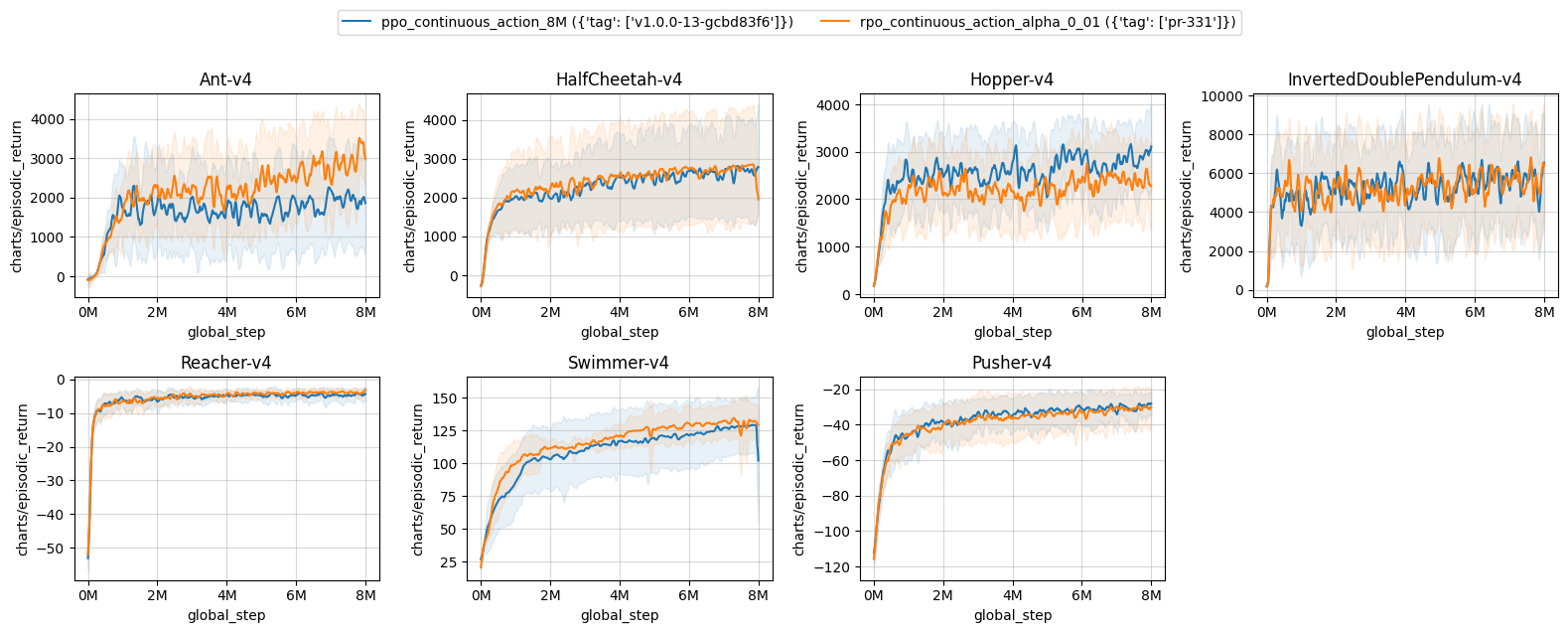
Tracked experiments:
Results with rpo_alpha=0.5 (not tuned) on the tuned environments:
| ppo_continuous_action_8M ({'tag': ['v1.0.0-13-gcbd83f6']}) | rpo_continuous_action ({'tag': ['pr-331']}) | |
|---|---|---|
| Ant-v4 | 1774.42 ± 819.08 | -7.99 ± 2.47 |
| HalfCheetah-v4 | 2667.34 ± 1109.99 | 2163.57 ± 790.16 |
| Hopper-v4 | 2761.77 ± 286.88 | 1557.18 ± 206.74 |
| InvertedDoublePendulum-v4 | 5644.00 ± 353.46 | 296.97 ± 15.95 |
| Reacher-v4 | -4.67 ± 0.88 | -66.35 ± 0.66 |
| Swimmer-v4 | 124.52 ± 22.10 | 117.82 ± 10.07 |
| Pusher-v4 | -30.62 ± 6.80 | -276.32 ± 26.99 |
Learning curves:
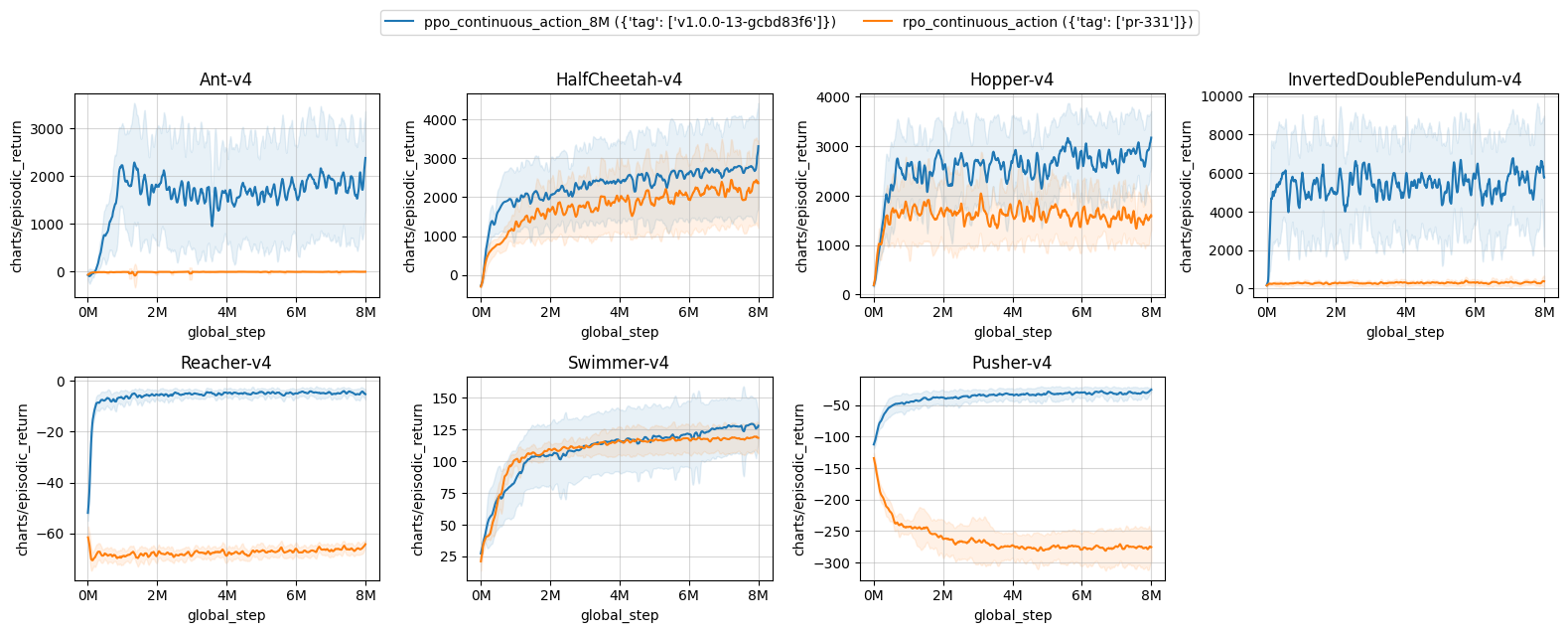
Tracked experiments:
| ppo_continuous_action_8M ({'tag': ['v1.0.0-13-gcbd83f6']}) | rpo_continuous_action ({'tag': ['pr-331']}) | |
|---|---|---|
| HumanoidStandup-v2 | 109118.07 ± 19422.20 | 156848.90 ± 11414.50 |
| Humanoid-v2 | 588.22 ± 43.80 | 717.37 ± 97.18 |
| InvertedPendulum-v2 | 867.64 ± 19.97 | 866.60 ± 27.06 |
| Walker2d-v2 | 3220.99 ± 923.84 | 4150.51 ± 348.03 |
Learning curves:
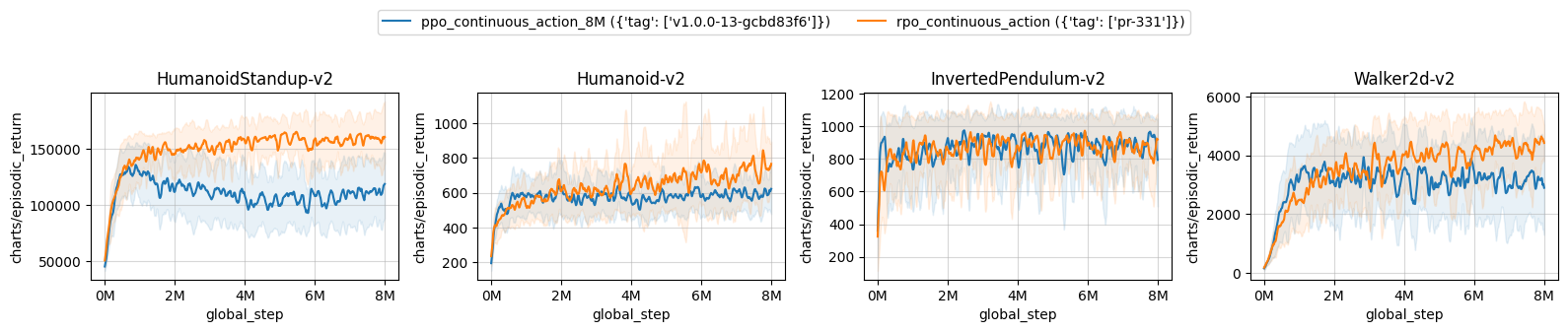
Tracked experiments:
The following environments require tuning of alpha (Algorithm 1, line 13, paper: https://arxiv.org/pdf/2212.07536.pdf). As described in the paper, this variable should be tuned for environments tested. A larger value means more randomness, whereas a smaller value indicates less randomness. Some mujoco environments require a smaller alpha=0.01 value to achieve a reasonable performance compared to alpha=0.5 for the rest of the environments. This version (alpha=0.01) of runs is indicated as rpo_continuous_action_alpha_0_01 in the table and learning curves.
| ppo_continuous_action_8M ({'tag': ['v1.0.0-13-gcbd83f6']}) | rpo_continuous_action_alpha_0_01 ({'tag': ['pr-331']}) | |
|---|---|---|
| Ant-v2 | 2412.35 ± 949.44 | 3084.95 ± 759.51 |
| HalfCheetah-v2 | 2717.27 ± 1269.85 | 2707.91 ± 1215.21 |
| Hopper-v2 | 2387.39 ± 645.41 | 2272.78 ± 588.66 |
| InvertedDoublePendulum-v2 | 5630.91 ± 377.93 | 5661.29 ± 316.04 |
| Reacher-v2 | -4.61 ± 0.53 | -4.24 ± 0.25 |
| Swimmer-v2 | 132.07 ± 9.92 | 141.37 ± 8.70 |
| Pusher-v2 | -33.93 ± 8.55 | -26.22 ± 2.52 |
Learning curves:
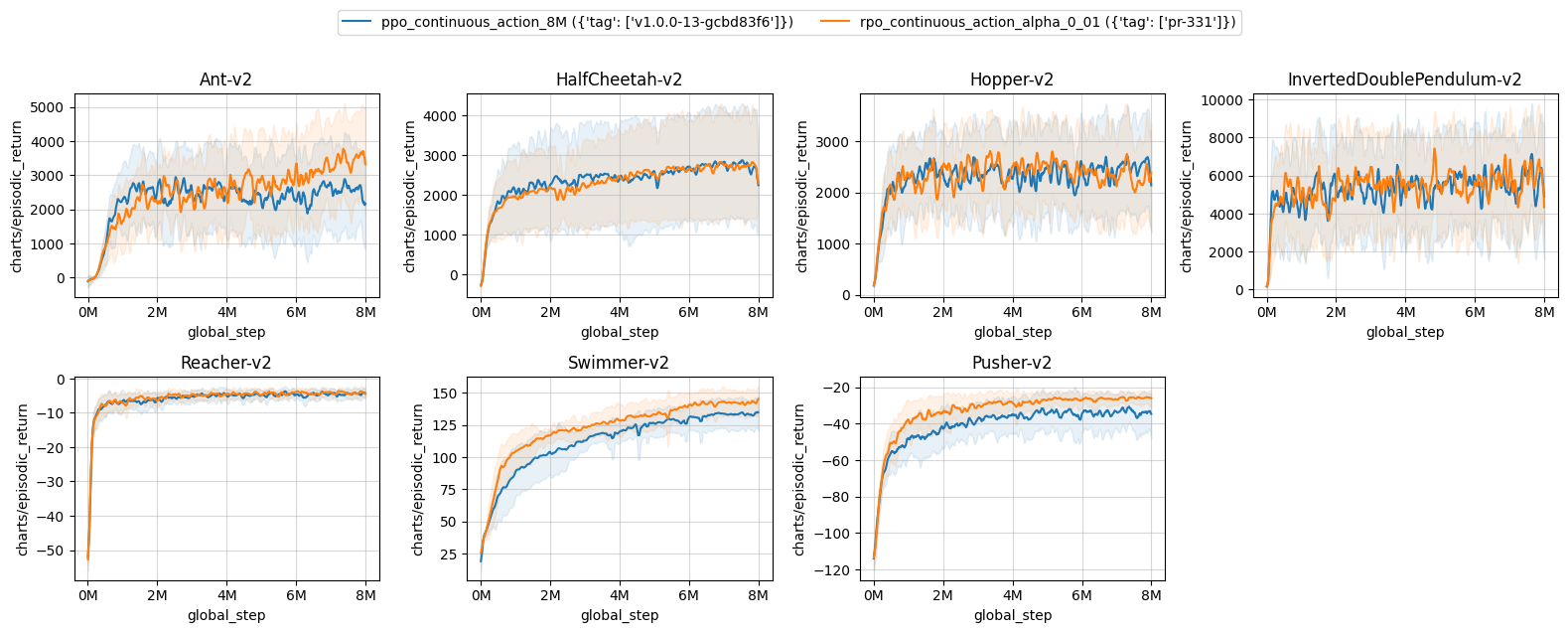
Tracked experiments:
Results with rpo_alpha=0.5 (not tuned) on the tuned environments:
| ppo_continuous_action_8M ({'tag': ['v1.0.0-13-gcbd83f6']}) | rpo_continuous_action ({'tag': ['pr-331']}) | |
|---|---|---|
| Ant-v2 | 2495.65 ± 991.65 | -7.81 ± 3.57 |
| HalfCheetah-v2 | 2722.03 ± 1231.28 | 2605.06 ± 1183.30 |
| Hopper-v2 | 2356.83 ± 650.91 | 1609.79 ± 164.16 |
| InvertedDoublePendulum-v2 | 5675.31 ± 244.34 | 274.78 ± 16.40 |
| Reacher-v2 | -4.67 ± 0.48 | -66.55 ± 0.20 |
| Swimmer-v2 | 131.53 ± 9.94 | 114.34 ± 3.95 |
| Pusher-v2 | -33.46 ± 8.41 | -275.09 ± 15.65 |
Learning curves:
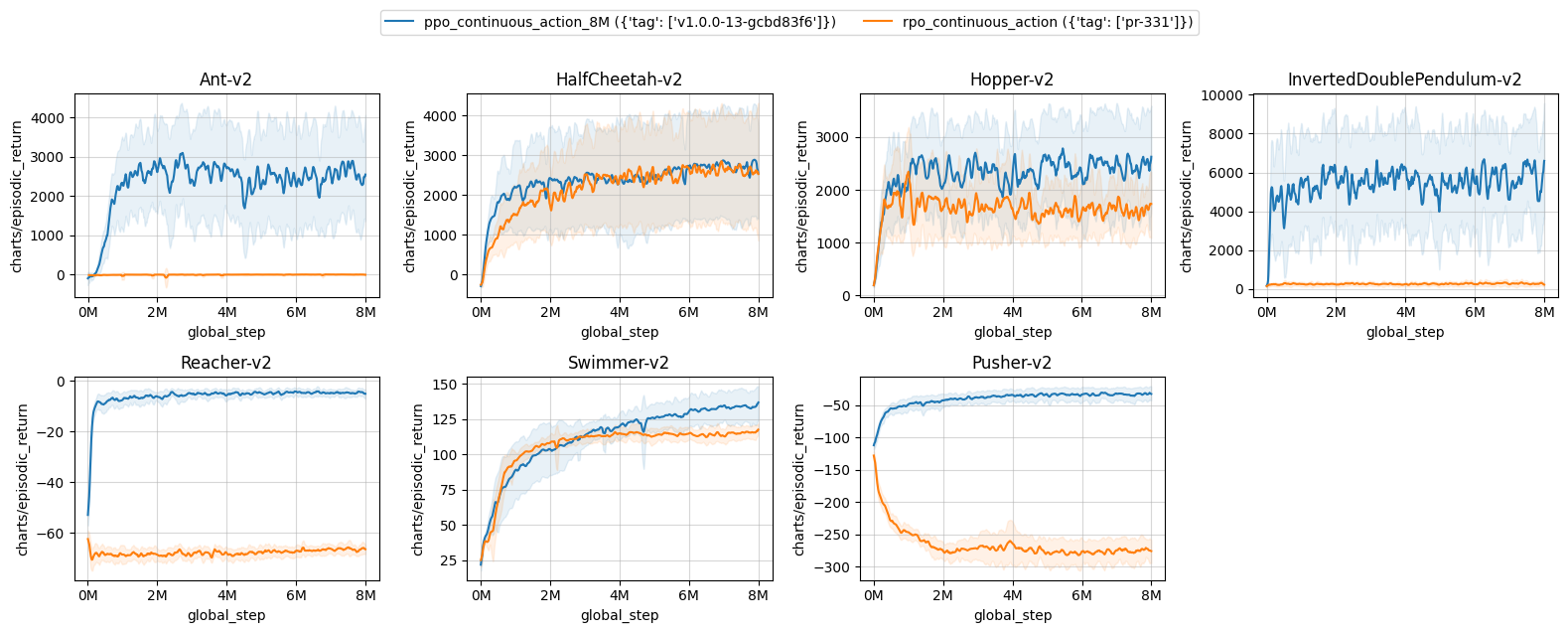
Tracked experiments:
Results on two continuous gym environments. The PPO and RPO run for 8M timesteps, and results are computed over 10 random seeds.
| ppo_continuous_action_8M ({'tag': ['v1.0.0-13-gcbd83f6']}) | rpo_continuous_action ({'tag': ['pr-331']}) | |
|---|---|---|
| Pendulum-v1 | -1141.98 ± 135.55 | -151.08 ± 3.73 |
| BipedalWalker-v3 | 172.12 ± 96.05 | 227.11 ± 18.23 |
Learning curves:
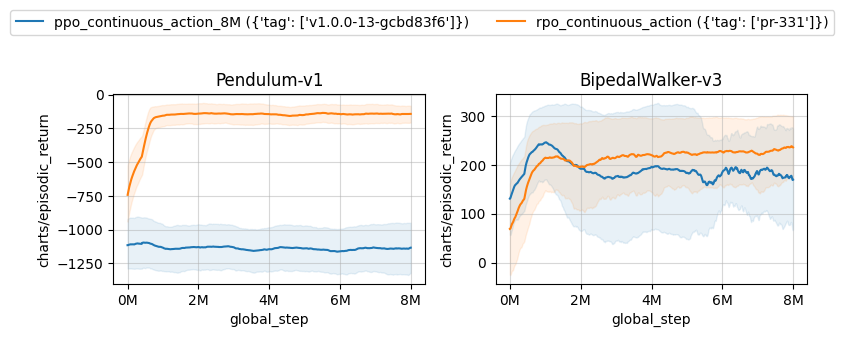
Tracked experiments:
Failure
Failure case of rpo_alpha=0.5:
Overall, we observed that rpo_alpha=0.5 is strictly equal to or better than the default PPO in 93% of environments tested (all 48/48 dm_control, 2/2 Gym, 7/11 mujoco_v4. Total 57 out of 61 environments tested).
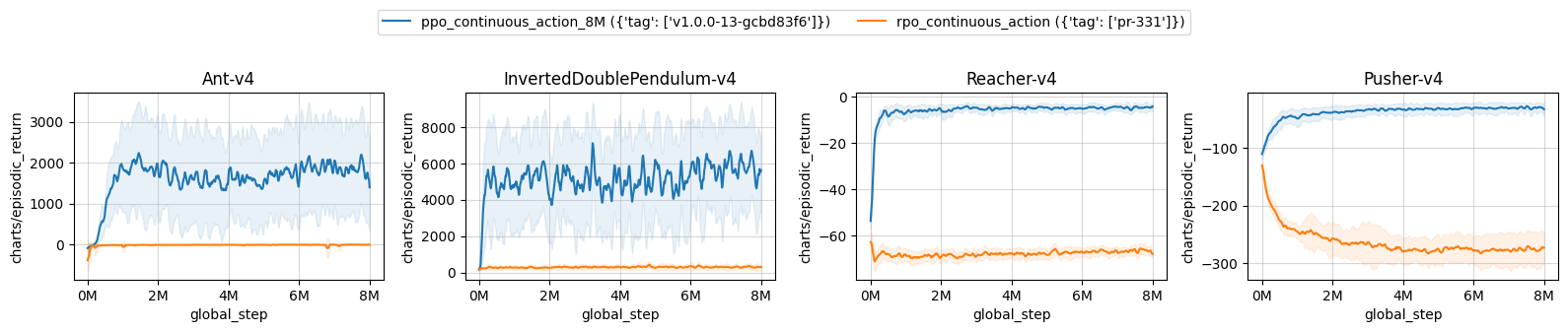
Here are the failure cases:
Mujoco v4 and v2: Ant InvertedDoublePendulum Reacher Pusher
| ppo_continuous_action_8M ({'tag': ['v1.0.0-13-gcbd83f6']}) | rpo_continuous_action ({'tag': ['pr-331']}) | |
|---|---|---|
| Ant-v4 | 1831.63 ± 867.71 | -10.43 ± 8.16 |
| InvertedDoublePendulum-v4 | 5490.71 ± 261.50 | 303.36 ± 13.39 |
| Reacher-v4 | -4.58 ± 0.73 | -66.62 ± 0.56 |
| Pusher-v4 | -30.63 ± 6.42 | -276.11 ± 26.52 |
Learning curves:
Tracked experiments:
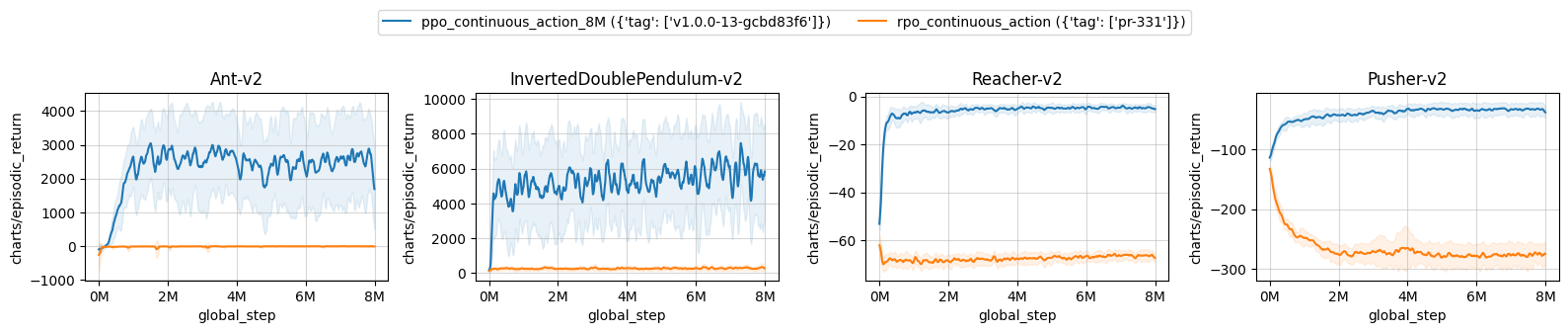
| ppo_continuous_action_8M ({'tag': ['v1.0.0-13-gcbd83f6']}) | rpo_continuous_action ({'tag': ['pr-331']}) | |
|---|---|---|
| Ant-v2 | 2493.50 ± 993.24 | -7.26 ± 2.28 |
| InvertedDoublePendulum-v2 | 5568.37 ± 401.65 | 278.94 ± 15.34 |
| Reacher-v2 | -4.62 ± 0.47 | -66.61 ± 0.23 |
| Pusher-v2 | -33.51 ± 8.47 | -276.01 ± 15.93 |
Learning curves:
Tracked experiments:
However, tuning of rpo_alpha (rpo_alpha=0.01 on failed cases) helps RPO to overcome the failure, and it performs strictly equal to or better than the default PPO in all (100%) of tested environments.