Basic Usage
Two Ways to Run
After the dependencies have been installed, there are two ways to run the CleanRL script under the uv virtual environments.
-
Using
uv run:uv run python cleanrl/ppo.py \ --seed 1 \ --env-id CartPole-v0 \ --total-timesteps 50000 -
Using
uv venv:- We first activate the virtual environment by using
uv venv - Then, run any desired CleanRL script
Attention: Each step must be executed separately!
uv venvpython cleanrl/ppo.py \ --seed 1 \ --env-id CartPole-v0 \ --total-timesteps 50000 - We first activate the virtual environment by using
Note
We recommend uv venv workflow for development. When the shell is activated, you should
be seeing a prefix like (cleanrl-iXg02GqF-py3.9) in your shell's prompt, which is the name
of the poetry's virtual environment.
We will assume to run other commands (e.g. tensorboard) in the documentation within the poetry's shell.
Warning
If you are using NVIDIA ampere GPUs (e.g., 3060 TI), you might meet the following error
NVIDIA GeForce RTX 3060 Ti with CUDA capability sm_86 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_70.
If you want to use the NVIDIA GeForce RTX 3060 Ti GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/
warnings.warn(incompatible_device_warn.format(device_name, capability, " ".join(arch_list), device_name))
Traceback (most recent call last):
File "ppo_atari_envpool.py", line 240, in <module>
action, logprob, _, value = agent.get_action_and_value(next_obs)
File "ppo_atari_envpool.py", line 156, in get_action_and_value
hidden = self.network(x / 255.0)
RuntimeError: CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
This is because the torch wheel on PyPi is built with cuda 10.2. You would need to manually install the cuda 11.3 wheel like this:
uv pip install torch==1.12.1 --upgrade --extra-index-url https://download.pytorch.org/whl/cu113
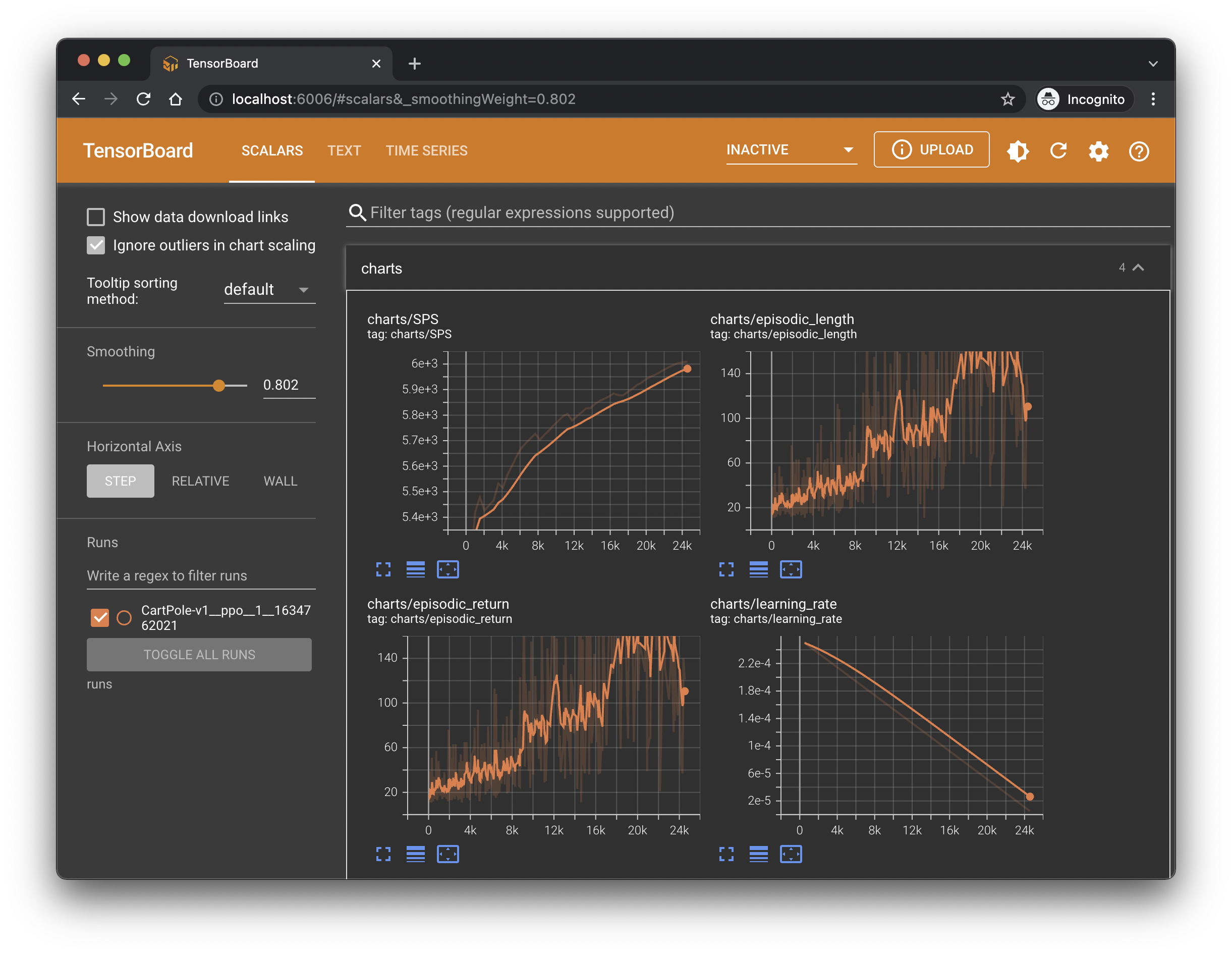
Visualize Training Metrics
By default, the CleanRL scripts record all the training metrics via Tensorboard
into the runs folder. So, after running the training script above, feel free to run
tensorboard --logdir runs
Visualize the Agent's Gameplay Videos
CleanRL helps record the agent's gameplay videos with a --capture_video flag,
which will save the videos in the videos/{$run_name} folder.
1 2 3 4 5 | |
Get Documentation
You can directly obtained the documentation by using the --help flag.
python cleanrl/ppo.py --help
usage: ppo.py [-h] [--exp-name EXP_NAME] [--env-id ENV_ID]
[--learning-rate LEARNING_RATE] [--seed SEED]
[--total-timesteps TOTAL_TIMESTEPS]
[--torch-deterministic [TORCH_DETERMINISTIC]] [--cuda [CUDA]]
[--track [TRACK]] [--wandb-project-name WANDB_PROJECT_NAME]
[--wandb-entity WANDB_ENTITY] [--capture_video [CAPTURE_VIDEO]]
[--num-envs NUM_ENVS] [--num-steps NUM_STEPS]
[--anneal-lr [ANNEAL_LR]] [--gae [GAE]] [--gamma GAMMA]
[--gae-lambda GAE_LAMBDA] [--num-minibatches NUM_MINIBATCHES]
[--update-epochs UPDATE_EPOCHS] [--norm-adv [NORM_ADV]]
[--clip-coef CLIP_COEF] [--clip-vloss [CLIP_VLOSS]]
[--ent-coef ENT_COEF] [--vf-coef VF_COEF]
[--max-grad-norm MAX_GRAD_NORM] [--target-kl TARGET_KL]
optional arguments:
-h, --help show this help message and exit
--exp-name EXP_NAME the name of this experiment
--env-id ENV_ID the id of the environment
--learning-rate LEARNING_RATE
the learning rate of the optimizer
--seed SEED seed of the experiment
--total-timesteps TOTAL_TIMESTEPS
total timesteps of the experiments
--torch-deterministic [TORCH_DETERMINISTIC]
if toggled, `torch.backends.cudnn.deterministic=False`
--cuda [CUDA] if toggled, cuda will be enabled by default
--track [TRACK] if toggled, this experiment will be tracked with Weights
and Biases
--wandb-project-name WANDB_PROJECT_NAME
the wandb's project name
--wandb-entity WANDB_ENTITY
the entity (team) of wandb's project
--capture_video [CAPTURE_VIDEO]
weather to capture videos of the agent performances (check
out `videos` folder)
--num-envs NUM_ENVS the number of parallel game environments
--num-steps NUM_STEPS
the number of steps to run in each environment per policy
rollout
--anneal-lr [ANNEAL_LR]
Toggle learning rate annealing for policy and value
networks
--gae [GAE] Use GAE for advantage computation
--gamma GAMMA the discount factor gamma
--gae-lambda GAE_LAMBDA
the lambda for the general advantage estimation
--num-minibatches NUM_MINIBATCHES
the number of mini-batches
--update-epochs UPDATE_EPOCHS
the K epochs to update the policy
--norm-adv [NORM_ADV]
Toggles advantages normalization
--clip-coef CLIP_COEF
the surrogate clipping coefficient
--clip-vloss [CLIP_VLOSS]
Toggles whether or not to use a clipped loss for the value
function, as per the paper.
--ent-coef ENT_COEF coefficient of the entropy
--vf-coef VF_COEF coefficient of the value function
--max-grad-norm MAX_GRAD_NORM
the maximum norm for the gradient clipping
--target-kl TARGET_KL
the target KL divergence threshold