Random Network Distillation (RND)
Overview
RND is an exploration bonus for RL methods that's easy to implement and enables significant progress in some hard exploration Atari games such as Montezuma's Revenge. We use Proximal Policy Gradient as our RL method as used by original paper's implementation
Original paper:
Implemented Variants
| Variants Implemented | Description |
|---|---|
ppo_rnd_envpool.py, docs |
For Atari games, uses EnvPool. |
Below are our single-file implementations of RND:
ppo_rnd_envpool.py
The ppo_rnd_envpool.py has the following features:
- Uses the blazing fast Envpool vectorized environment.
- For playing Atari games. It uses convolutional layers and common atari-based pre-processing techniques.
- Works with the Atari's pixel
Boxobservation space of shape(210, 160, 3) - Works with the
Discereteaction space
Warning
Note that ppo_rnd_envpool.py does not work in Windows and MacOs . See envpool's built wheels here: https://pypi.org/project/envpool/#files
Bug
EnvPool's vectorized environment does not behave the same as gym's vectorized environment, which causes a compatibility bug in our PPO implementation. When an action \(a\) results in an episode termination or truncation, the environment generates \(s_{last}\) as the terminated or truncated state; we then use \(s_{new}\) to denote the initial state of the new episodes. Here is how the bahviors differ:
- Under the vectorized environment of
envpool<=0.6.4, theobsinobs, reward, done, info = env.step(action)is the truncated state \(s_{last}\) - Under the vectorized environment of
gym==0.23.1, theobsinobs, reward, done, info = env.step(action)is the initial state \(s_{new}\).
This causes the \(s_{last}\) to be off by one. See sail-sg/envpool#194 for more detail. However, it does not seem to impact performance, so we take a note here and await for the upstream fix.
Usage
uv pip install ".[envpool]"
uv run python cleanrl/ppo_rnd_envpool.py --help
uv run python cleanrl/ppo_rnd_envpool.py --env-id MontezumaRevenge-v5
pip install -r requirements/requirements-envpool.txt
python cleanrl/ppo_rnd_envpool.py --help
python cleanrl/ppo_rnd_envpool.py --env-id MontezumaRevenge-v5
Explanation of the logged metrics
See related docs for ppo.py.
Below is the additional metric for RND:
charts/episode_curiosity_reward: episodic intrinsic rewards.losses/fwd_loss: the prediction error between predict network and target network, can also be viewed as a proxy of the curiosity reward in that batch.
Implementation details
ppo_rnd_envpool.py uses a customized RecordEpisodeStatistics to work with envpool but has the same other implementation details as ppo_atari.py (see related docs). Additionally, it has the following additional details:
- We initialize the normalization parameters by stepping a random agent in the environment by
args.num_steps * args.num_iterations_obs_norm_init.args.num_iterations_obs_norm_init=50comes from the original implementation. - We uses sticky action from envpool to facilitate the exploration like done in the original implementation.
Experiment results
To run benchmark experiments, see benchmark/rnd.sh. Specifically, execute the following command:
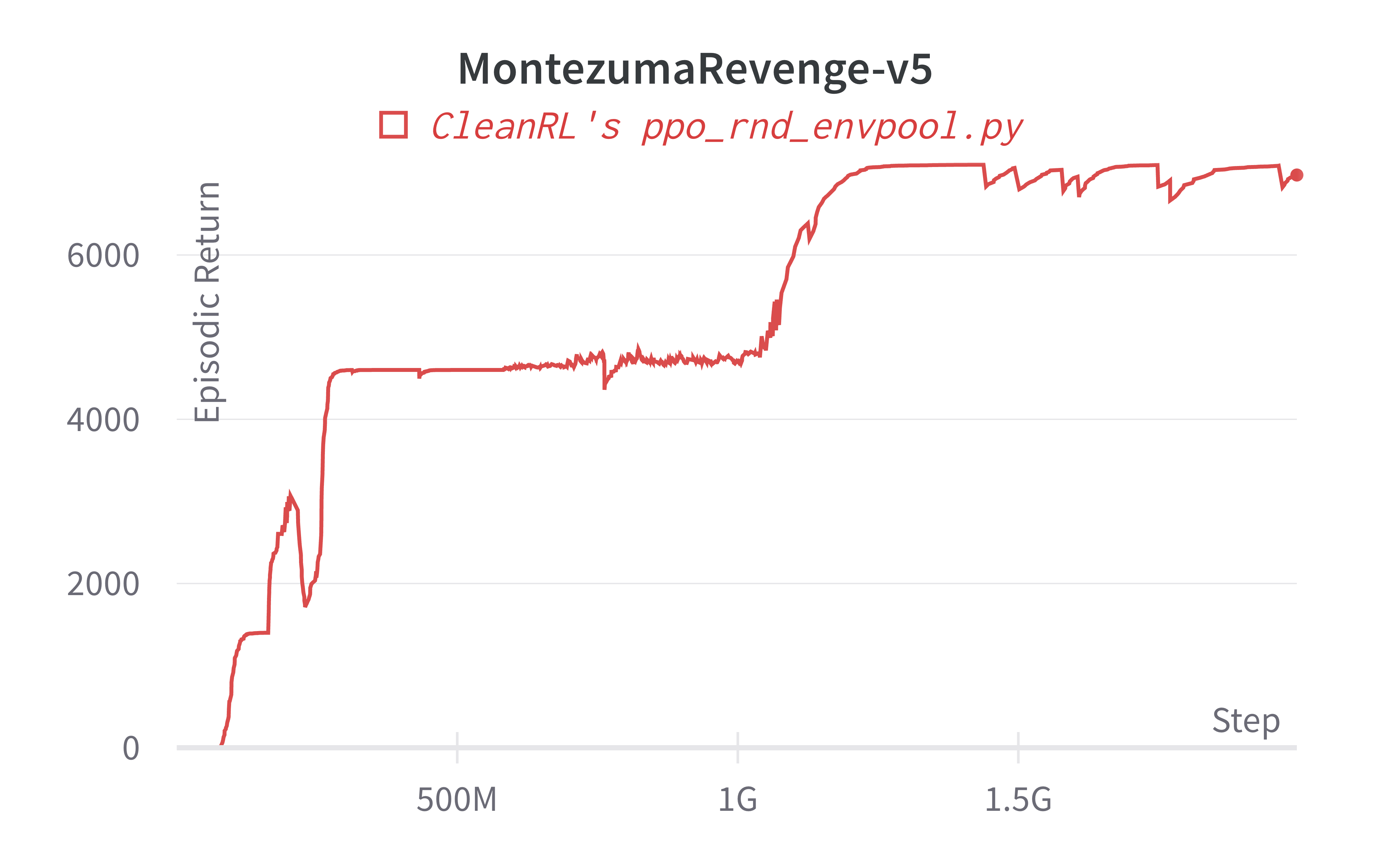
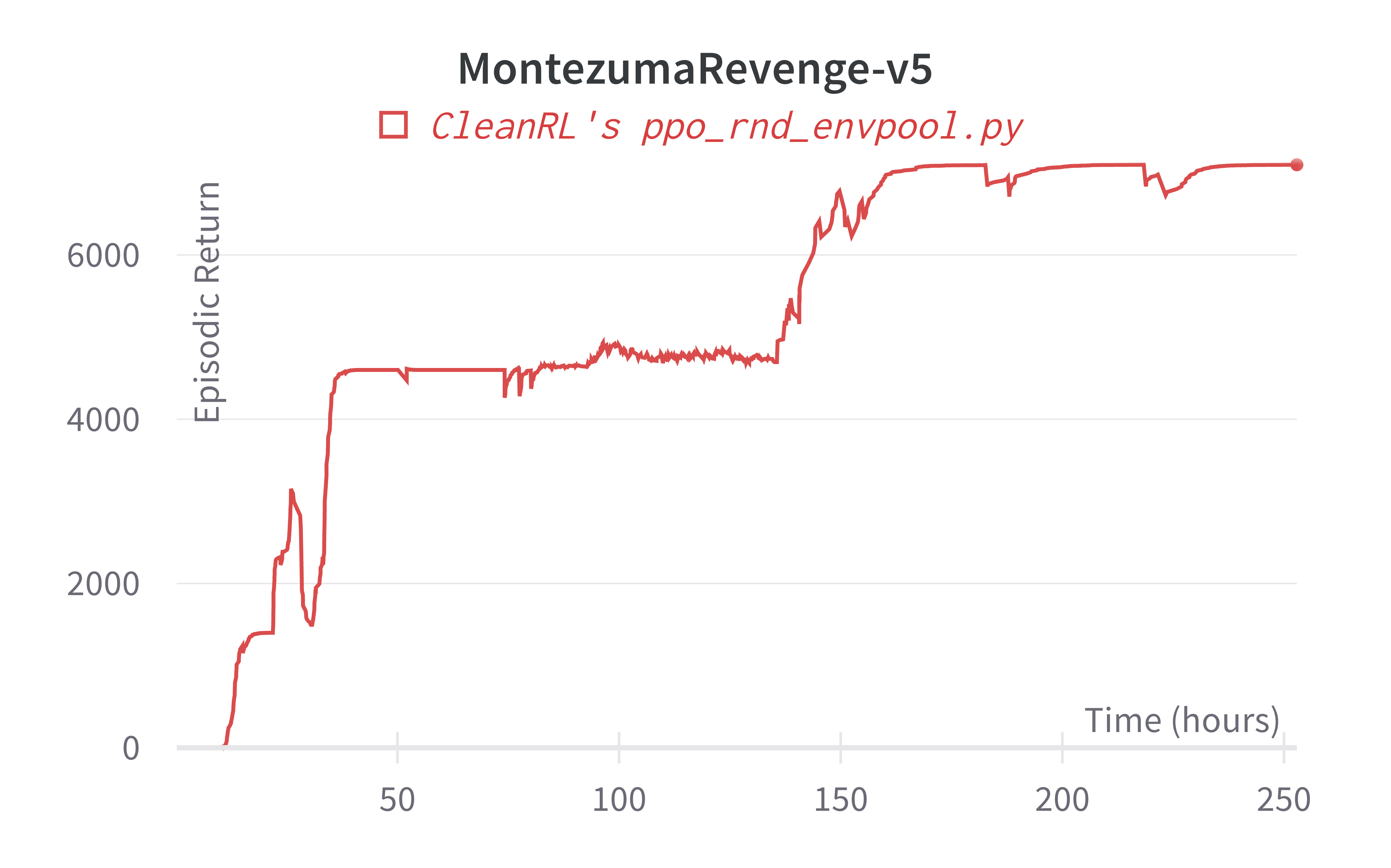
Below are the average episodic returns for ppo_rnd_envpool.py. To ensure the quality of the implementation, we compared the results against openai/random-network-distillation' PPO.
| Environment | ppo_rnd_envpool.py |
(Burda et al., 2019, Figure 7)1 2000M steps |
|---|---|---|
| MontezumaRevengeNoFrameSkip-v4 | 7100 (1 seed) | 8152 (3 seeds) |
Note the MontezumaRevengeNoFrameSkip-v4 has same setting to MontezumaRevenge-v5. Our benchmark has one seed due to limited compute resource and extreme long run time (~250 hours).
Learning curves:
Tracked experiments and game play videos:
-
Burda, Yuri, et al. "Exploration by random network distillation." Seventh International Conference on Learning Representations. 2019. ↩