Categorical DQN (C51)
Overview
C51 introduces a distributional perspective for DQN: instead of learning a single value for an action, C51 learns to predict a distribution of values for the action. Empirically, C51 demonstrates impressive performance in ALE.
Original papers:
Implemented Variants
| Variants Implemented | Description |
|---|---|
c51_atari.py, docs |
For playing Atari games. It uses convolutional layers and common atari-based pre-processing techniques. |
c51.py, docs |
For classic control tasks like CartPole-v1. |
c51_atari_jax.py, docs |
For playing Atari games. It uses convolutional layers and common atari-based pre-processing techniques. |
c51_jax.py, docs |
For classic control tasks like CartPole-v1. |
Below are our single-file implementations of C51:
c51_atari.py
The c51_atari.py has the following features:
- For playing Atari games. It uses convolutional layers and common atari-based pre-processing techniques.
- Works with the Atari's pixel
Boxobservation space of shape(210, 160, 3) - Works with the
Discreteaction space
Usage
uv pip install ".[atari]"
uv run python cleanrl/c51_atari.py --env-id BreakoutNoFrameskip-v4
uv run python cleanrl/c51_atari.py --env-id PongNoFrameskip-v4
pip install -r requirements/requirements-atari.txt
python cleanrl/c51_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/c51_atari.py --env-id PongNoFrameskip-v4
Explanation of the logged metrics
Running python cleanrl/c51_atari.py will automatically record various metrics such as actor or value losses in Tensorboard. Below is the documentation for these metrics:
charts/episodic_return: episodic return of the gamecharts/SPS: number of steps per secondlosses/loss: the cross entropy loss between the \(t\) step state value distribution and the projected \(t+1\) step state value distributionlosses/q_values: implemented as(old_pmfs * q_network.atoms).sum(1), which is the sum of the probability of getting returns \(x\) (old_pmfs) multiplied by \(x\) (q_network.atoms), averaged over the sample obtained from the replay buffer; useful when gauging if under or over estimation happens
Implementation details
c51_atari.py is based on (Bellemare et al., 2017)1 but presents a few implementation differences:
- (Bellemare et al., 2017)1 injects stochaticity by doing "on each frame the environment rejects the agent’s selected action with probability \(p = 0.25\)", but
c51_atari.pydoes not do this c51_atari.pyuse a self-contained evaluation scheme:c51_atari.pyreports the episodic returns obtained throughout training, whereas (Bellemare et al., 2017)1 is trained with--end-e=0.01but reported episodic returns using a separate evaluation process with--end-e=0.001(See "5.2. State-of-the-Art Results" on page 7).
Experiment results
To run benchmark experiments, see benchmark/c51.sh. Specifically, execute the following command:
Below are the average episodic returns for c51_atari.py.
| Environment | c51_atari.py 10M steps |
(Bellemare et al., 2017, Figure 14)1 50M steps | (Hessel et al., 2017, Figure 5)3 |
|---|---|---|---|
| BreakoutNoFrameskip-v4 | 461.86 ± 69.65 | 748 | ~500 at 10M steps, ~600 at 50M steps |
| PongNoFrameskip-v4 | 19.46 ± 0.70 | 20.9 | ~20 10M steps, ~20 at 50M steps |
| BeamRiderNoFrameskip-v4 | 9592.90 ± 2270.15 | 14,074 | ~12000 10M steps, ~14000 at 50M steps |
Note that we save computational time by reducing timesteps from 50M to 10M, but our c51_atari.py scores the same or higher than (Mnih et al., 2015)1 in 10M steps.
Learning curves:
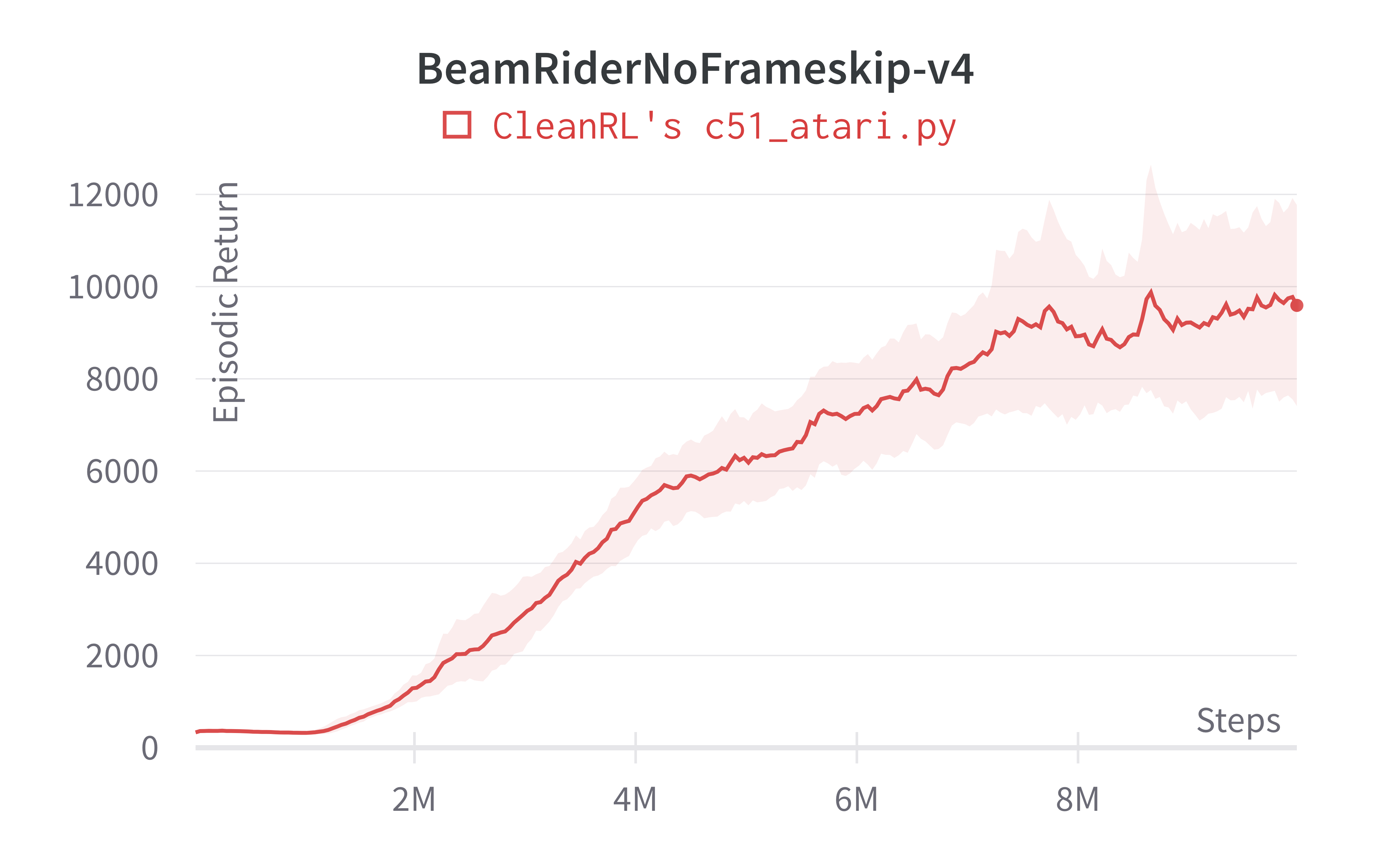
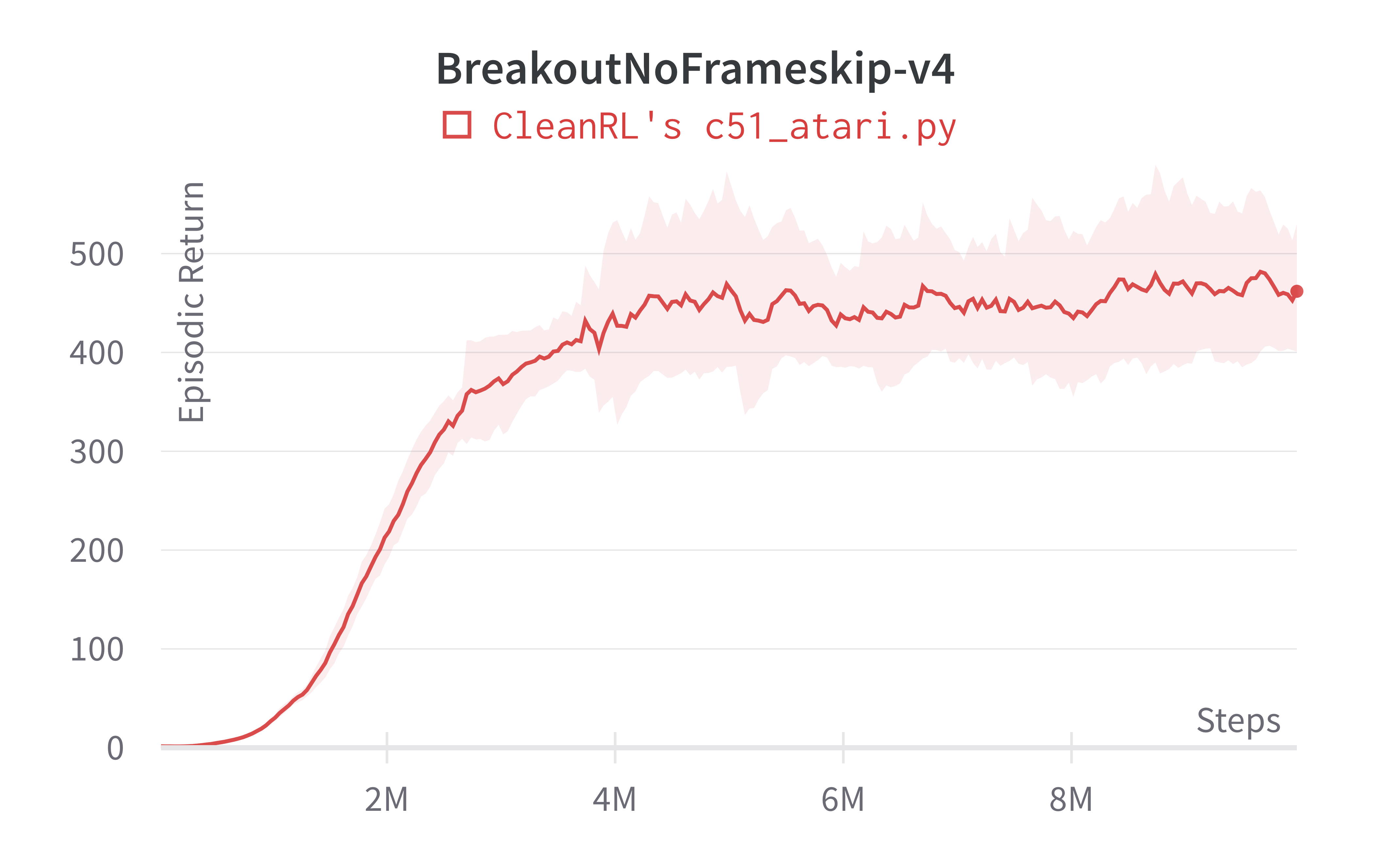
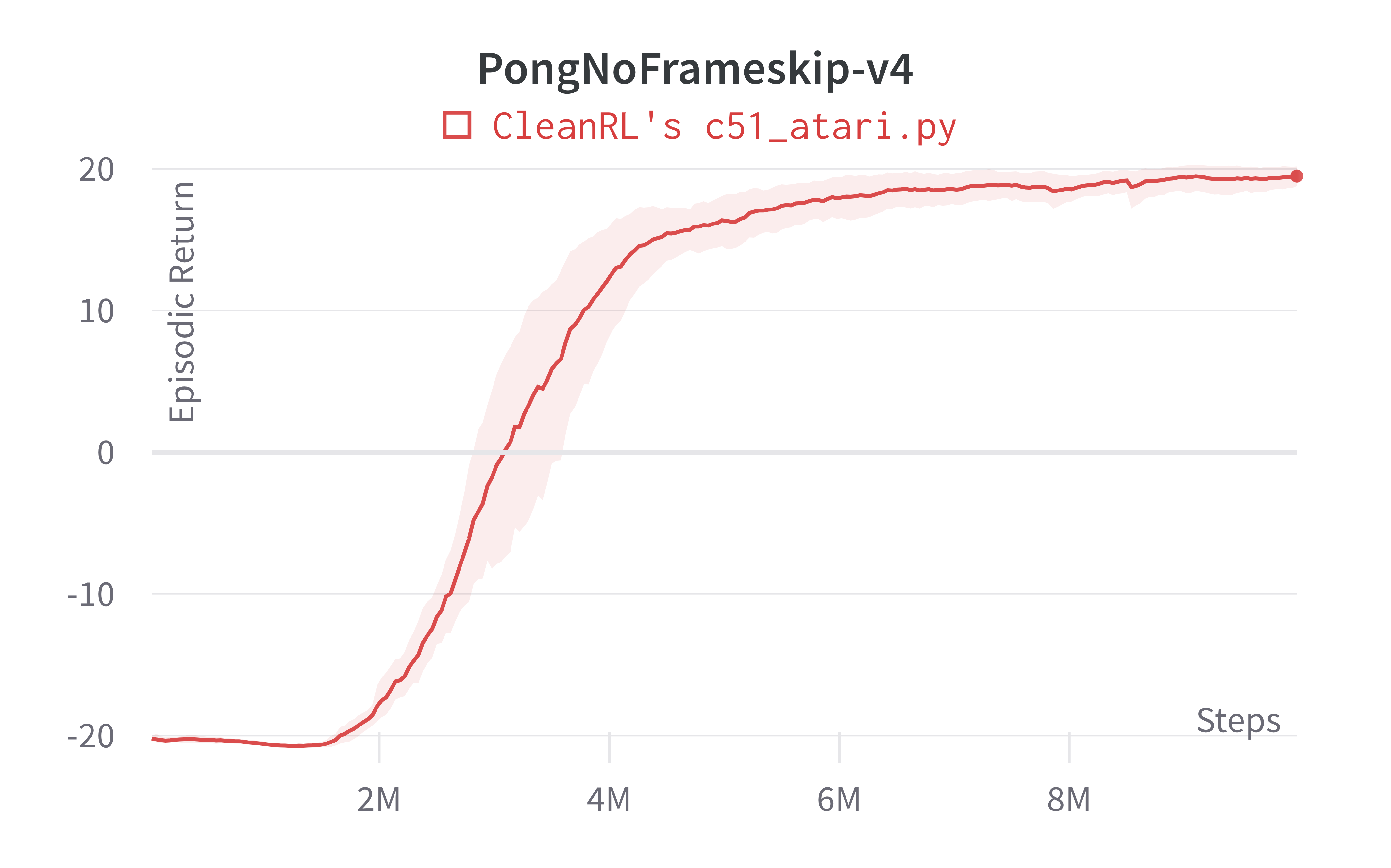
Tracked experiments and game play videos:
c51.py
The c51.py has the following features:
- Works with the
Boxobservation space of low-level features - Works with the
Discreteaction space - Works with envs like
CartPole-v1
Usage
uv run python cleanrl/c51.py --env-id CartPole-v1
python cleanrl/c51.py --env-id CartPole-v1
Explanation of the logged metrics
See related docs for c51_atari.py.
Implementation details
The c51.py shares the same implementation details as c51_atari.py except the c51.py runs with different hyperparameters and neural network architecture. Specifically,
c51.pyuses a simpler neural network as follows:self.network = nn.Sequential( nn.Linear(np.array(env.single_observation_space.shape).prod(), 120), nn.ReLU(), nn.Linear(120, 84), nn.ReLU(), nn.Linear(84, env.single_action_space.n), )-
c51.pyruns with different hyperparameters:python c51.py --total-timesteps 500000 \ --learning-rate 2.5e-4 \ --buffer-size 10000 \ --gamma 0.99 \ --target-network-frequency 500 \ --max-grad-norm 0.5 \ --batch-size 128 \ --start-e 1 \ --end-e 0.05 \ --exploration-fraction 0.5 \ --learning-starts 10000 \ --train-frequency 10
Experiment results
To run benchmark experiments, see benchmark/c51.sh. Specifically, execute the following command:
Below are the average episodic returns for c51.py.
| Environment | c51.py |
|---|---|
| CartPole-v1 | 481.20 ± 20.53 |
| Acrobot-v1 | -87.70 ± 5.52 |
| MountainCar-v0 | -166.38 ± 27.94 |
Note that the C51 has no official benchmark on classic control environments, so we did not include a comparison. That said, our c51.py was able to achieve near perfect scores in CartPole-v1 and Acrobot-v1; further, it can obtain successful runs in the sparse environment MountainCar-v0.
Learning curves:
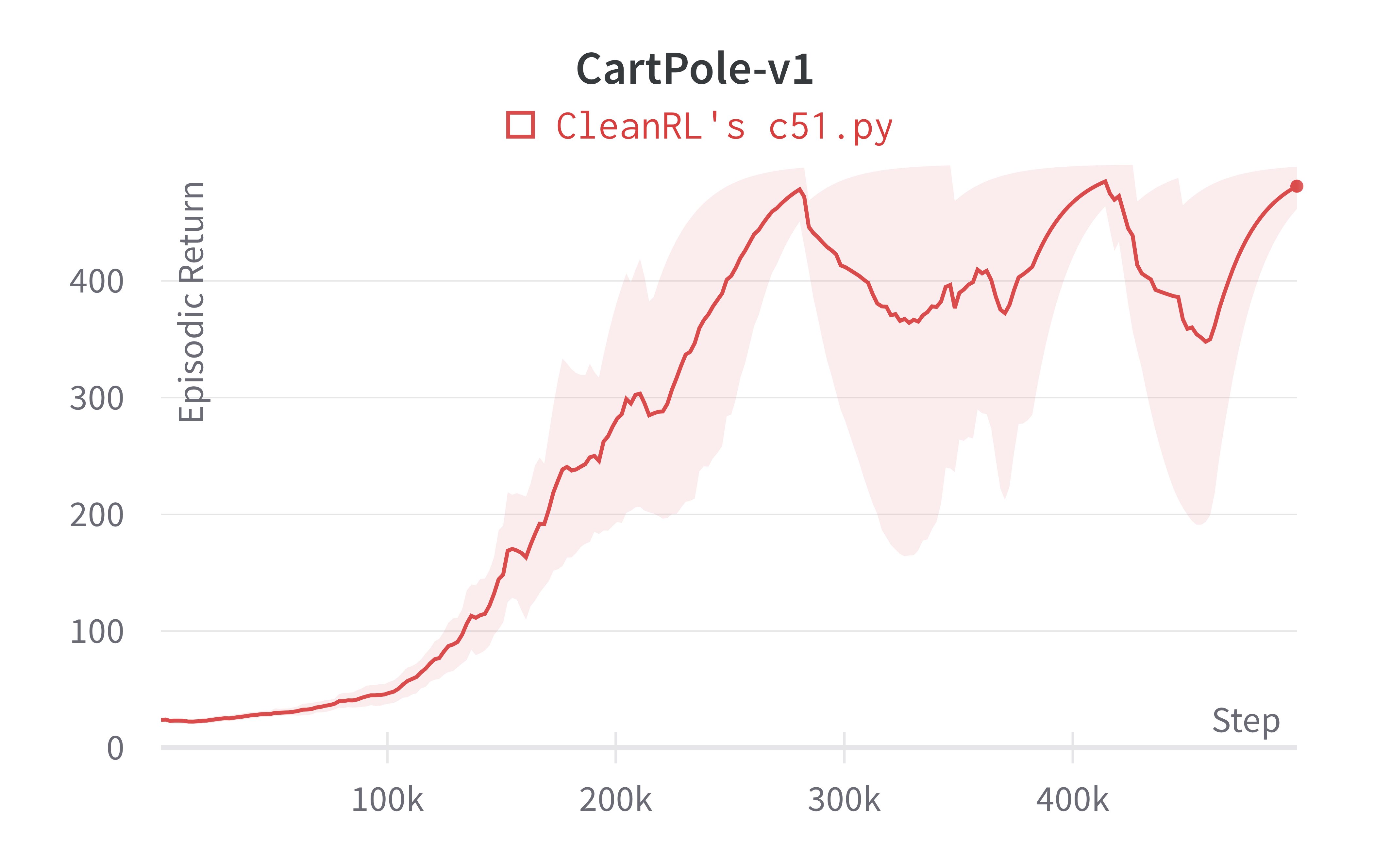
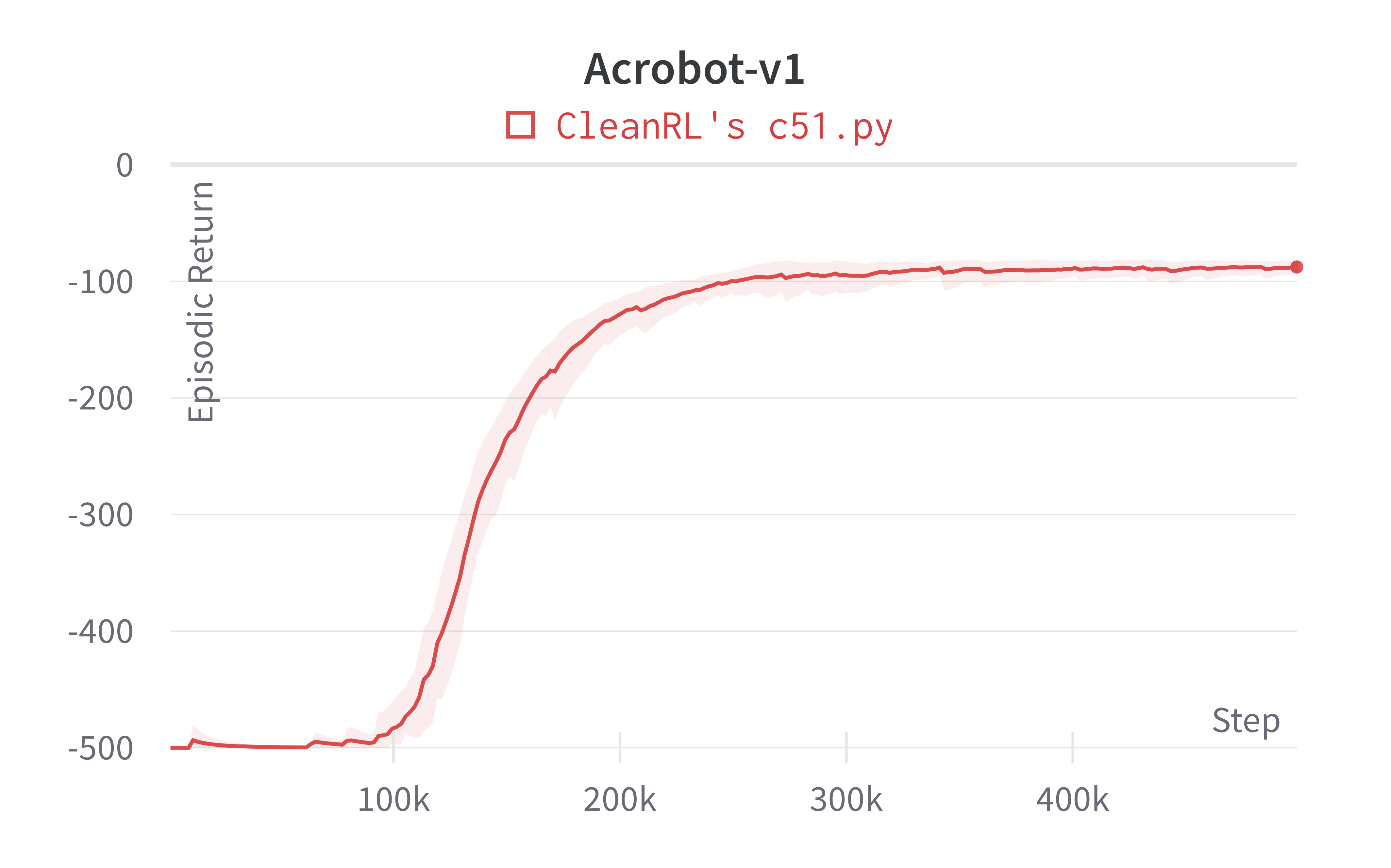
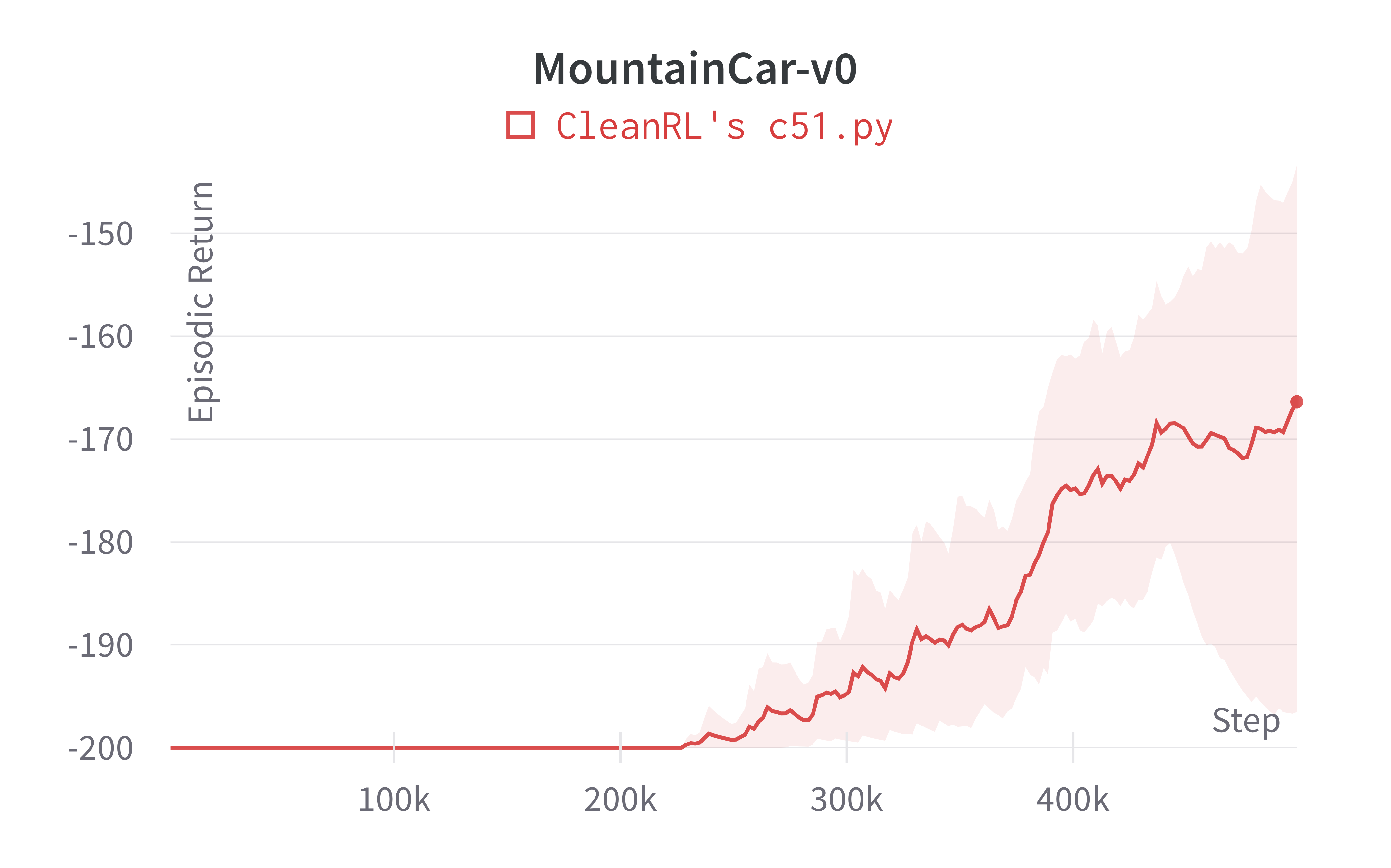
Tracked experiments and game play videos:
c51_atari_jax.py
The c51_atari_jax.py has the following features:
- Uses Jax, Flax, and Optax instead of
torch. c51_atari_jax.py is roughly 25% faster than c51_atari.py - For playing Atari games. It uses convolutional layers and common atari-based pre-processing techniques.
- Works with the Atari's pixel
Boxobservation space of shape(210, 160, 3) - Works with the
Discreteaction space
Usage
uv pip install ".[atari, jax]"
uv pip install --upgrade "jax[cuda11_cudnn82]==0.4.8" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
uv run python cleanrl/c51_atari_jax.py --env-id BreakoutNoFrameskip-v4
uv run python cleanrl/c51_atari_jax.py --env-id PongNoFrameskip-v4
pip install -r requirements/requirements-atari.txt
pip install -r requirements/requirements-jax.txt
pip install --upgrade "jax[cuda]==0.3.17" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
python cleanrl/c51_atari_jax.py --env-id BreakoutNoFrameskip-v4
python cleanrl/c51_atari_jax.py --env-id PongNoFrameskip-v4
Explanation of the logged metrics
See related docs for c51_atari.py.
Implementation details
See related docs for c51_atari.py.
Experiment results
To run benchmark experiments, see benchmark/c51.sh. Specifically, execute the following command:
Below are the average episodic returns for c51_atari_jax.py.
| Environment | c51_atari_jax.py 10M steps |
c51_atari.py 10M steps |
(Bellemare et al., 2017, Figure 14)1 50M steps | (Hessel et al., 2017, Figure 5)3 |
|---|---|---|---|---|
| BreakoutNoFrameskip-v4 | 448.56 ± 17.02 | 461.86 ± 69.65 | 748 | ~500 at 10M steps, ~600 at 50M steps |
| PongNoFrameskip-v4 | 19.88 ± 0.31 | 19.46 ± 0.70 | 20.9 | ~20 10M steps, ~20 at 50M steps |
| BeamRiderNoFrameskip-v4 | 9504.91 ± 709.69 | 9592.90 ± 2270.15 | 14,074 | ~12000 10M steps, ~14000 at 50M steps |
Learning curves:
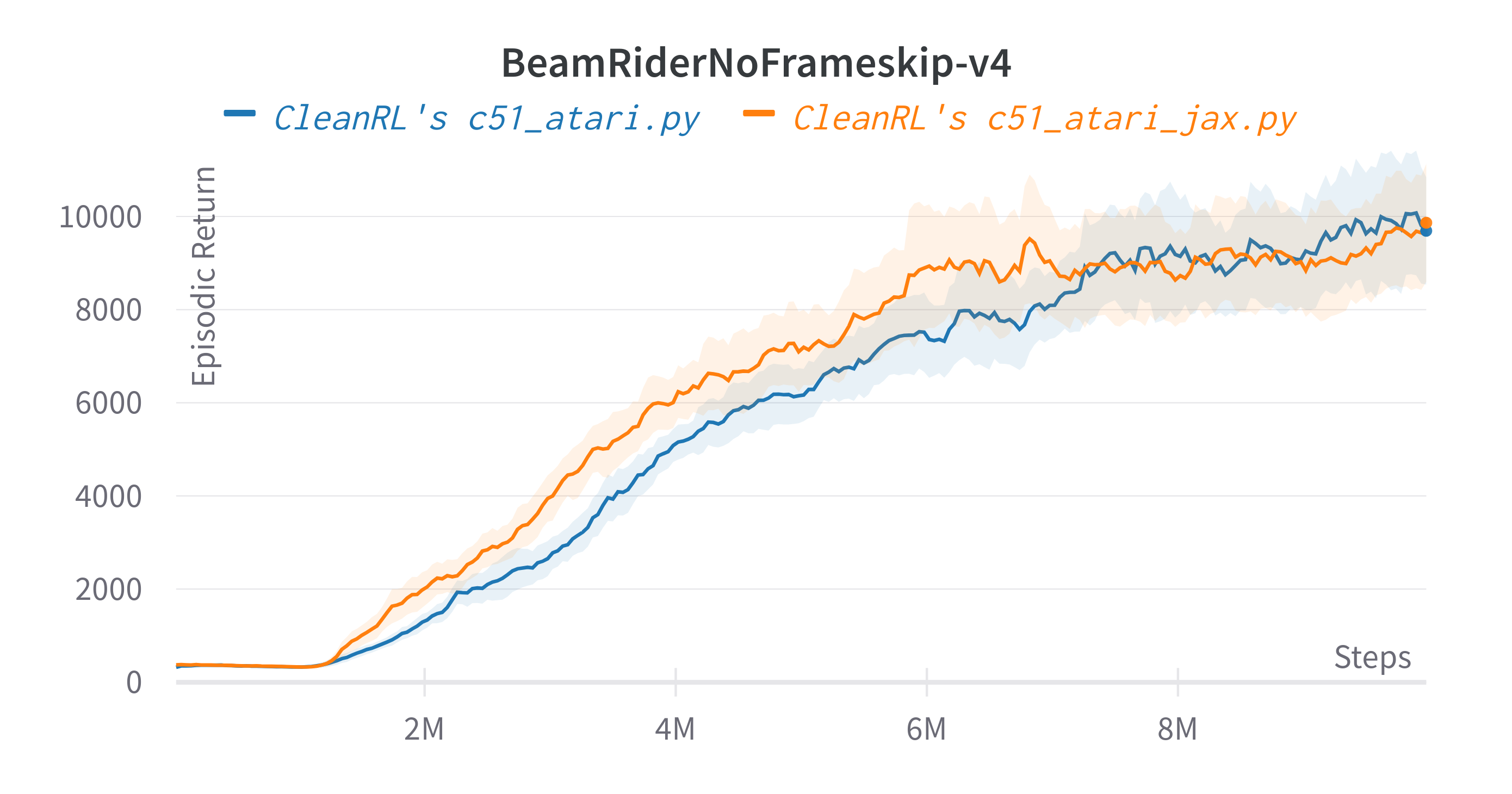
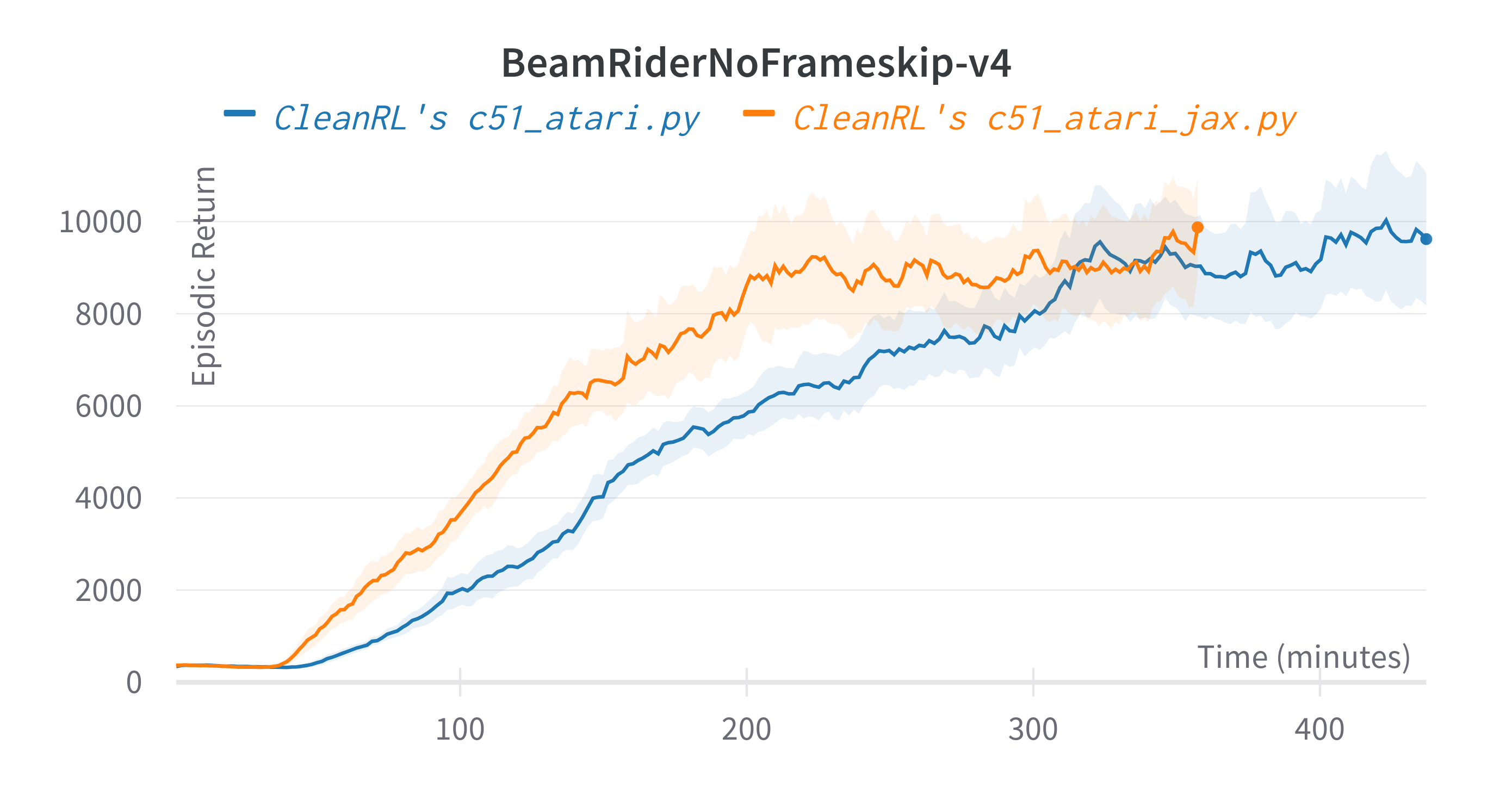
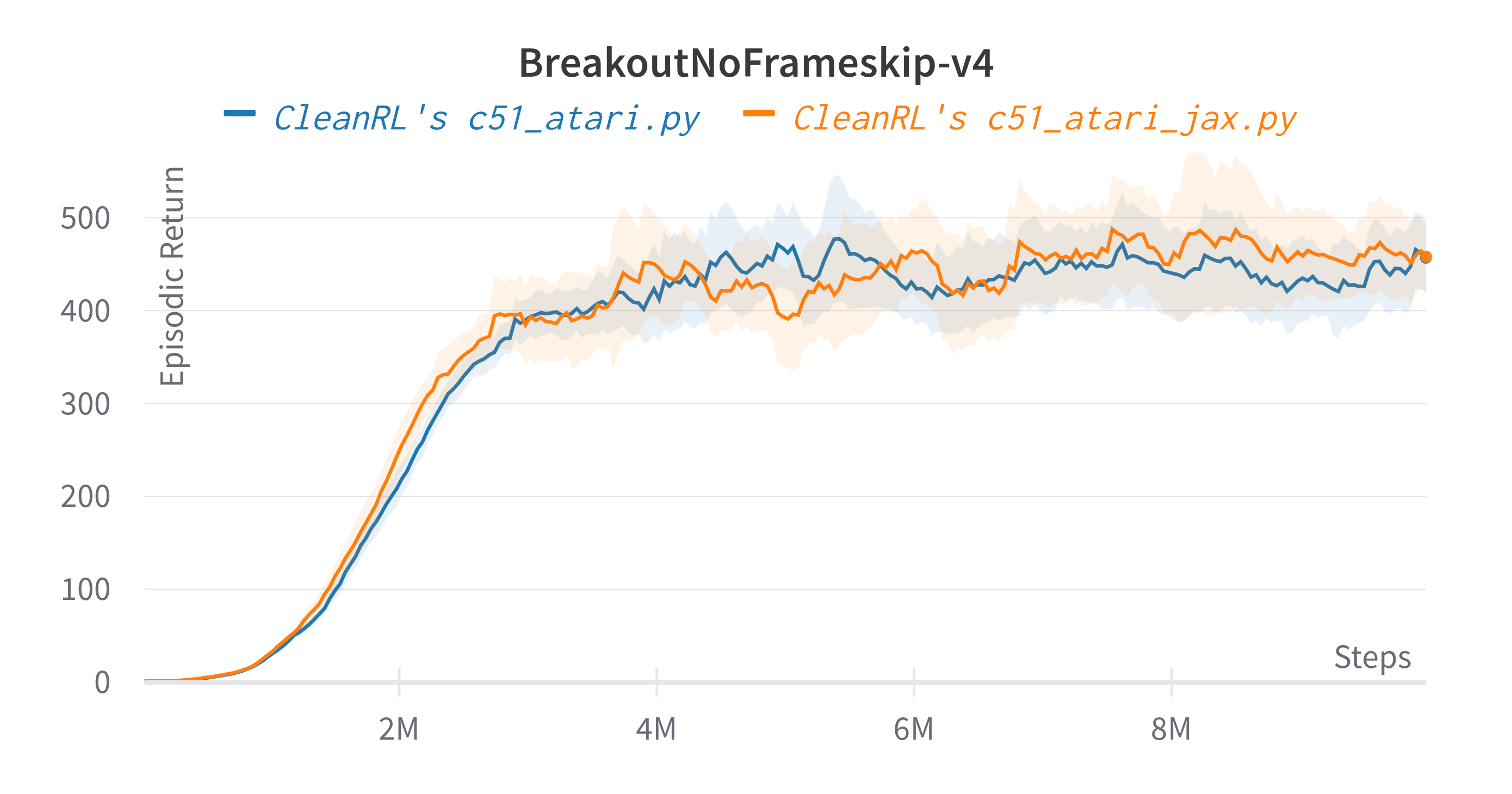
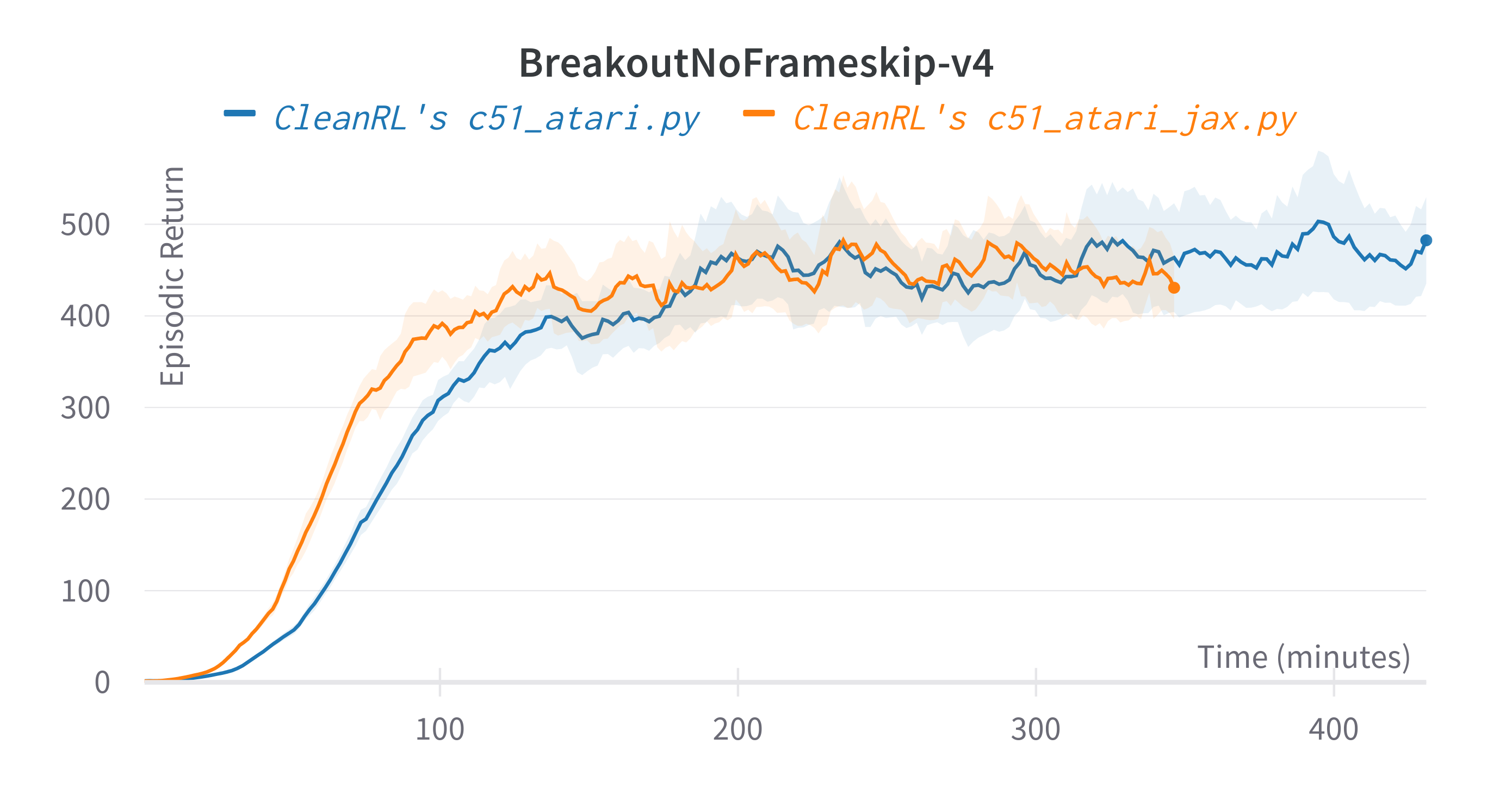
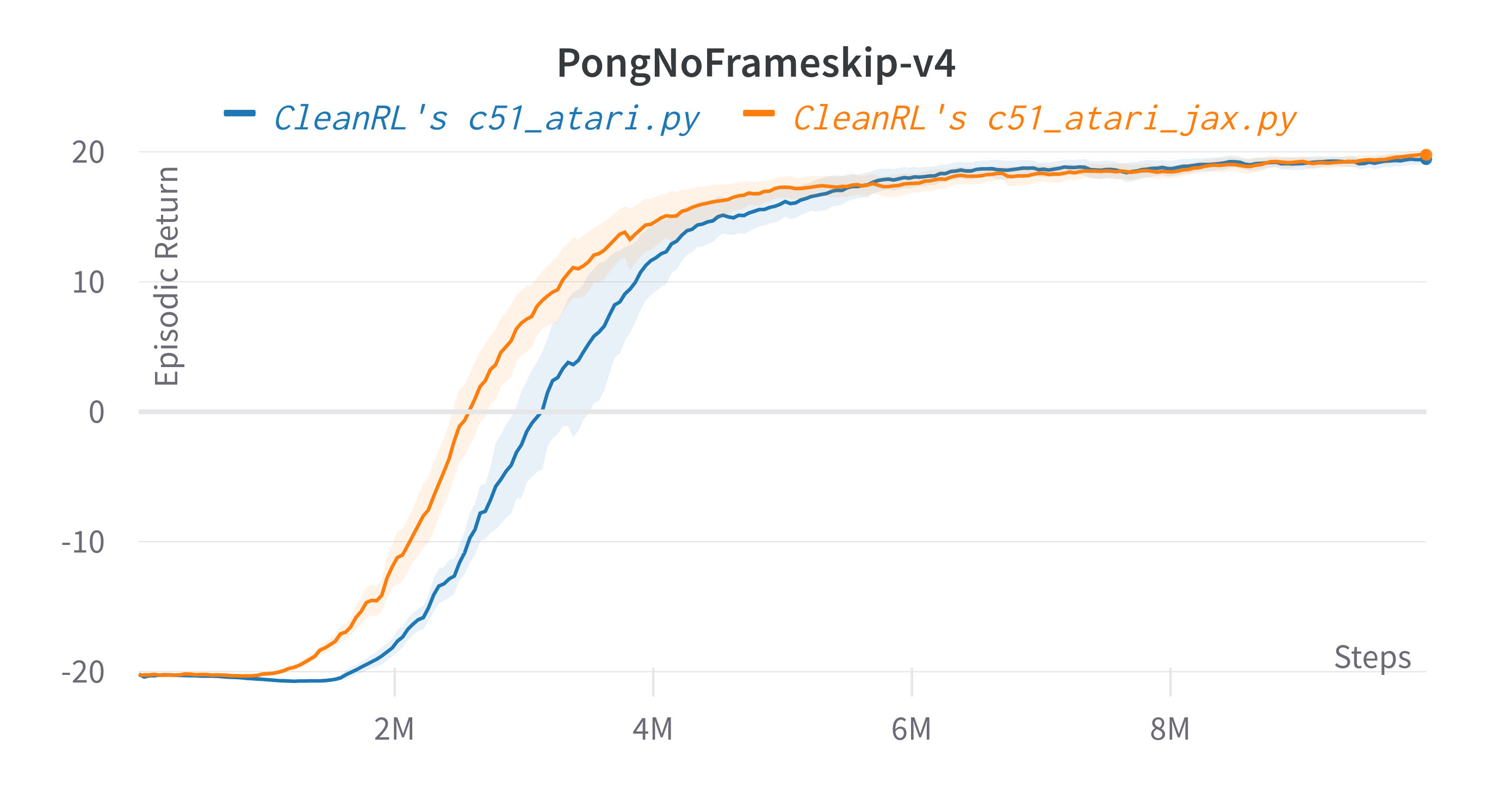
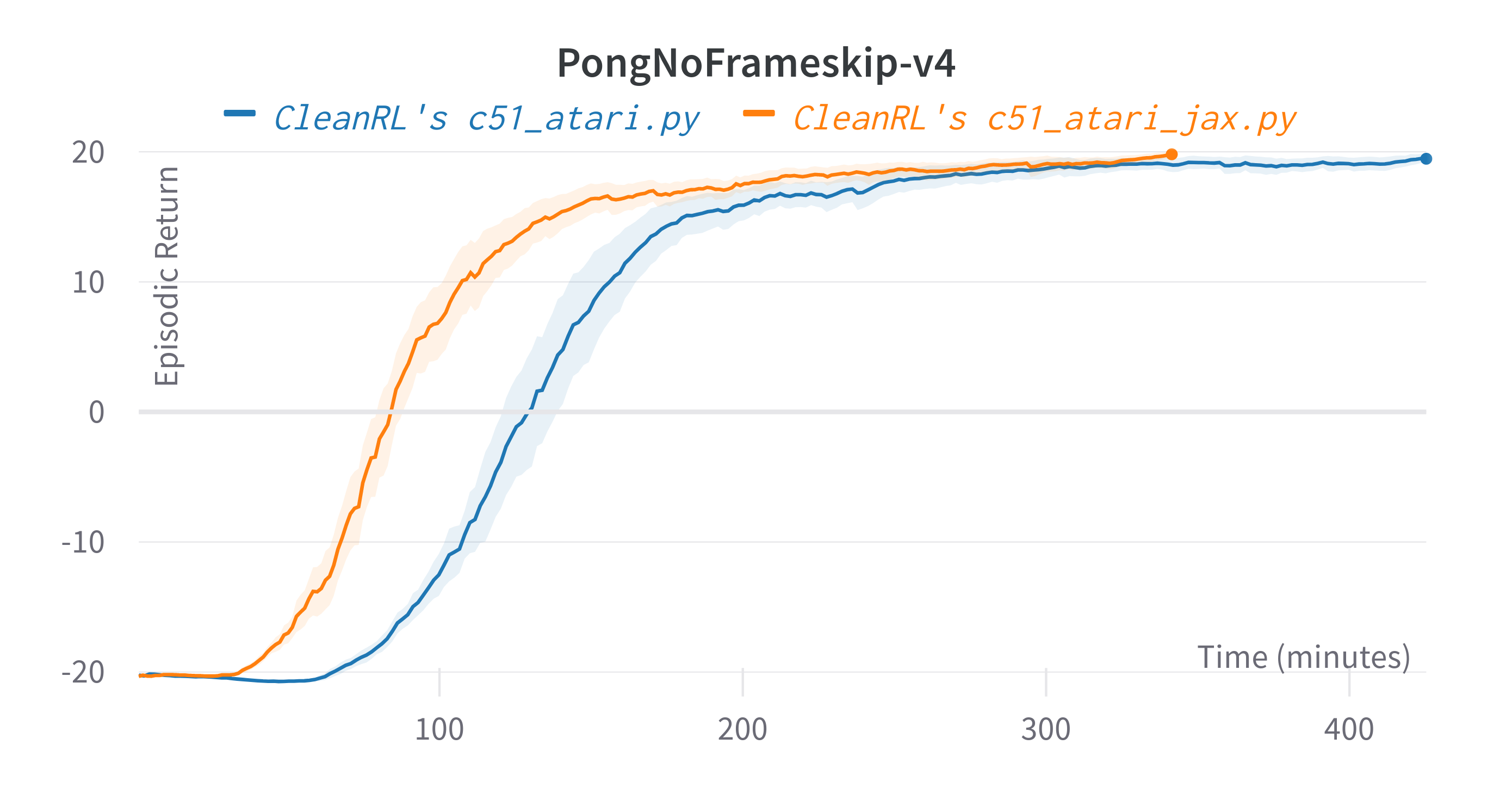
Tracked experiments and game play videos:
c51_jax.py
The c51_jax.py has the following features:
- Uses Jax, Flax, and Optax instead of
torch. c51_jax.py is roughly 55% faster than c51.py - Works with the
Boxobservation space of low-level features - Works with the
Discreteaction space - Works with envs like
CartPole-v1
Usage
uv pip install ".[jax]"
uv pip install --upgrade "jax[cuda11_cudnn82]==0.4.8" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
uv run python cleanrl/c51_jax.py --env-id CartPole-v1
pip install -r requirements/requirements-jax.txt
pip install --upgrade "jax[cuda]==0.3.17" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
python cleanrl/c51_jax.py --env-id CartPole-v1
Explanation of the logged metrics
See related docs for c51_atari.py.
Implementation details
See related docs for c51.py.
Experiment results
To run benchmark experiments, see benchmark/c51.sh. Specifically, execute the following command:
Below are the average episodic returns for c51_jax.py.
| Environment | c51_jax.py |
c51.py |
|---|---|---|
| CartPole-v1 | 491.07 ± 9.70 | 481.20 ± 20.53 |
| Acrobot-v1 | -86.74 ± 2.19 | -87.70 ± 5.52 |
| MountainCar-v0 | -174.30 ± 36.35 | -166.38 ± 27.94 |
Learning curves:
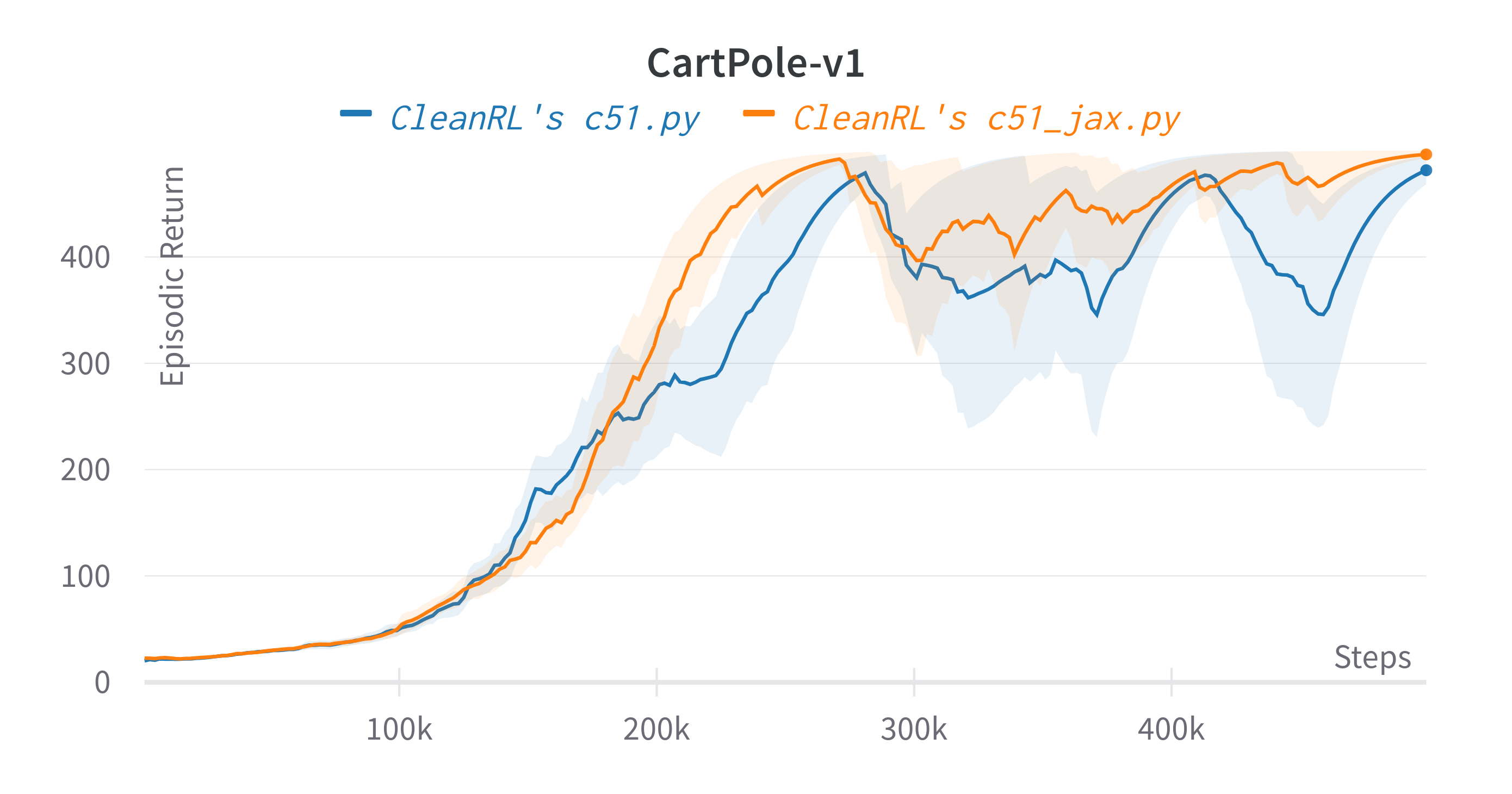
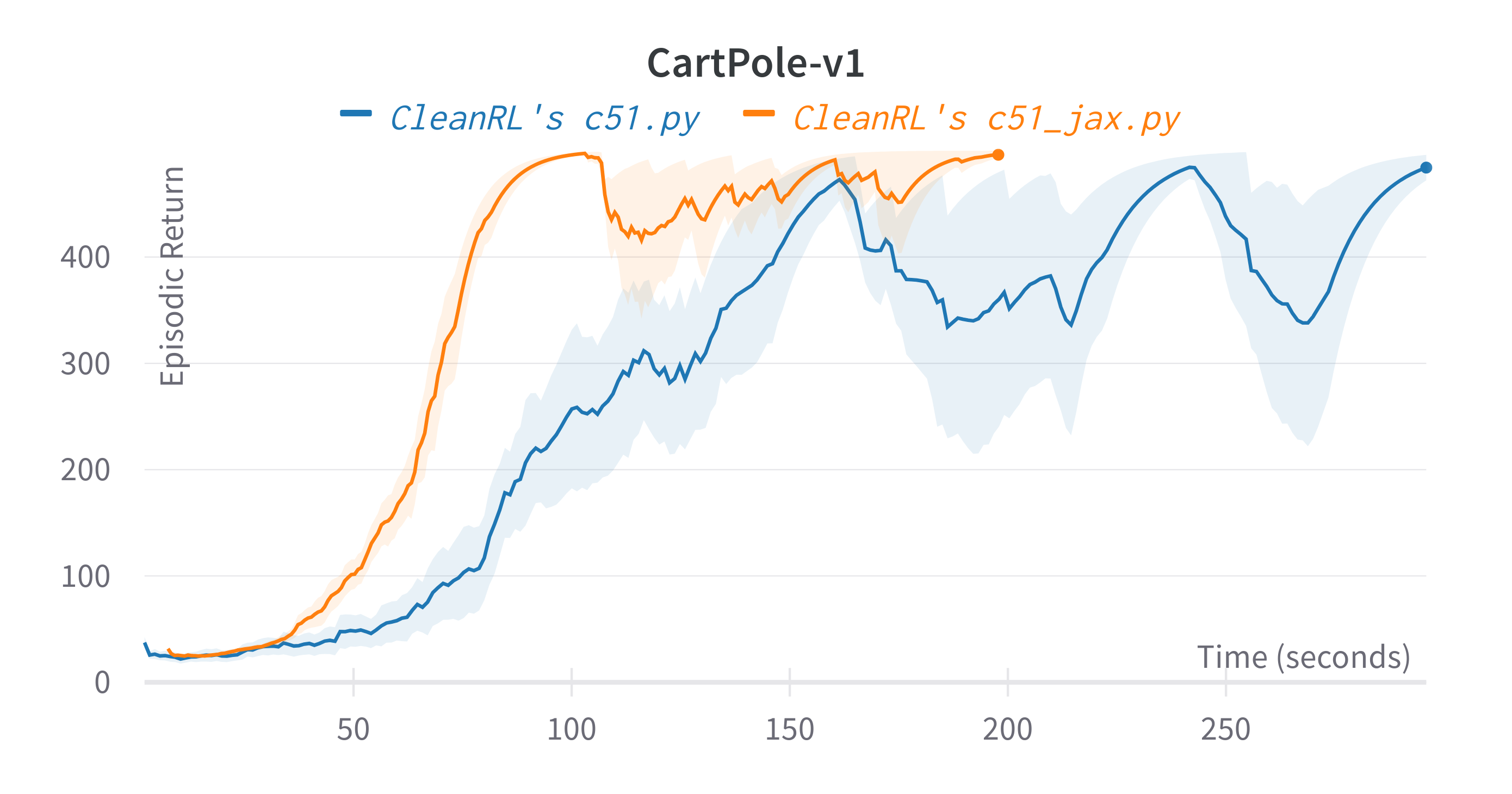
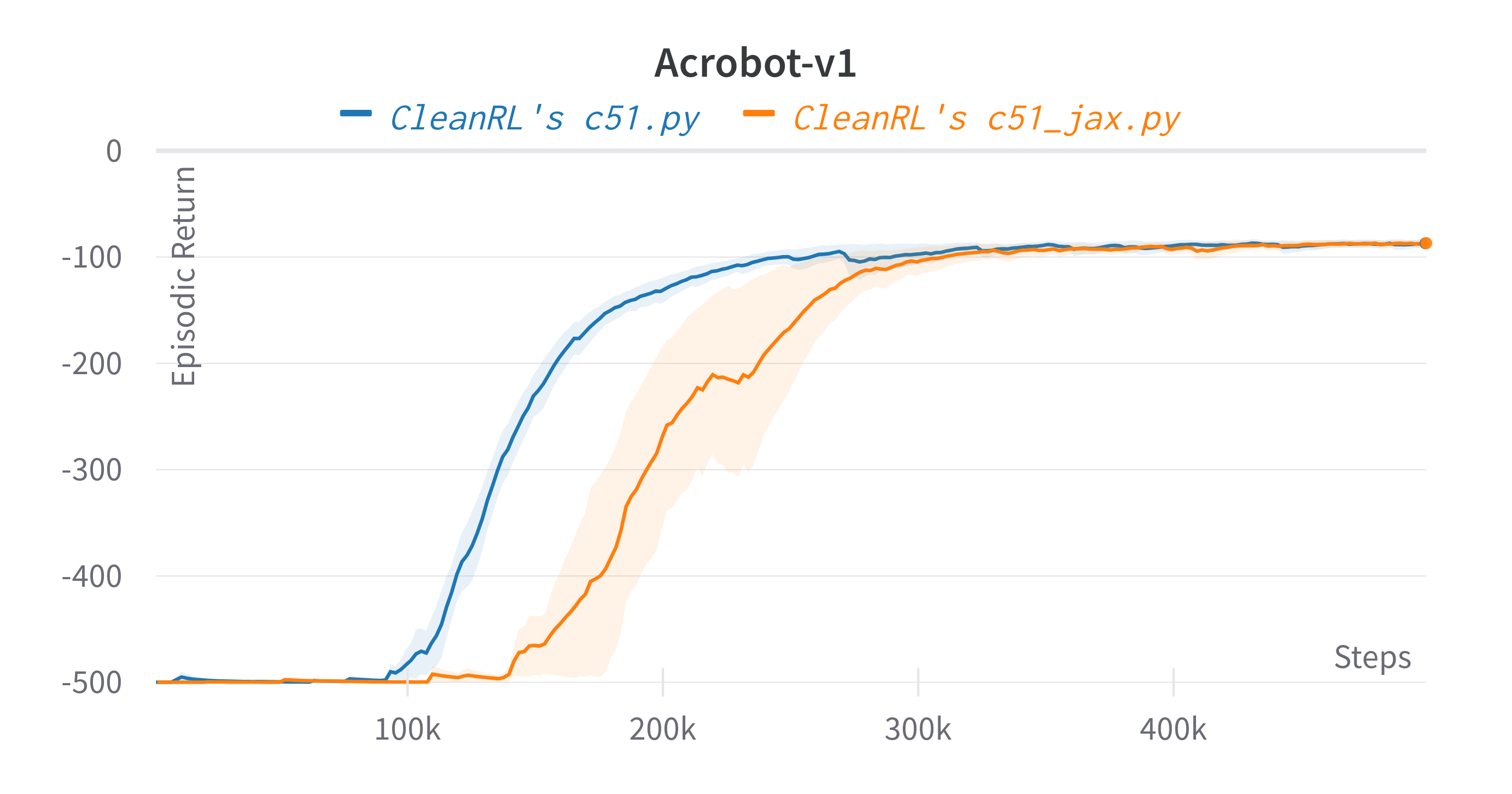
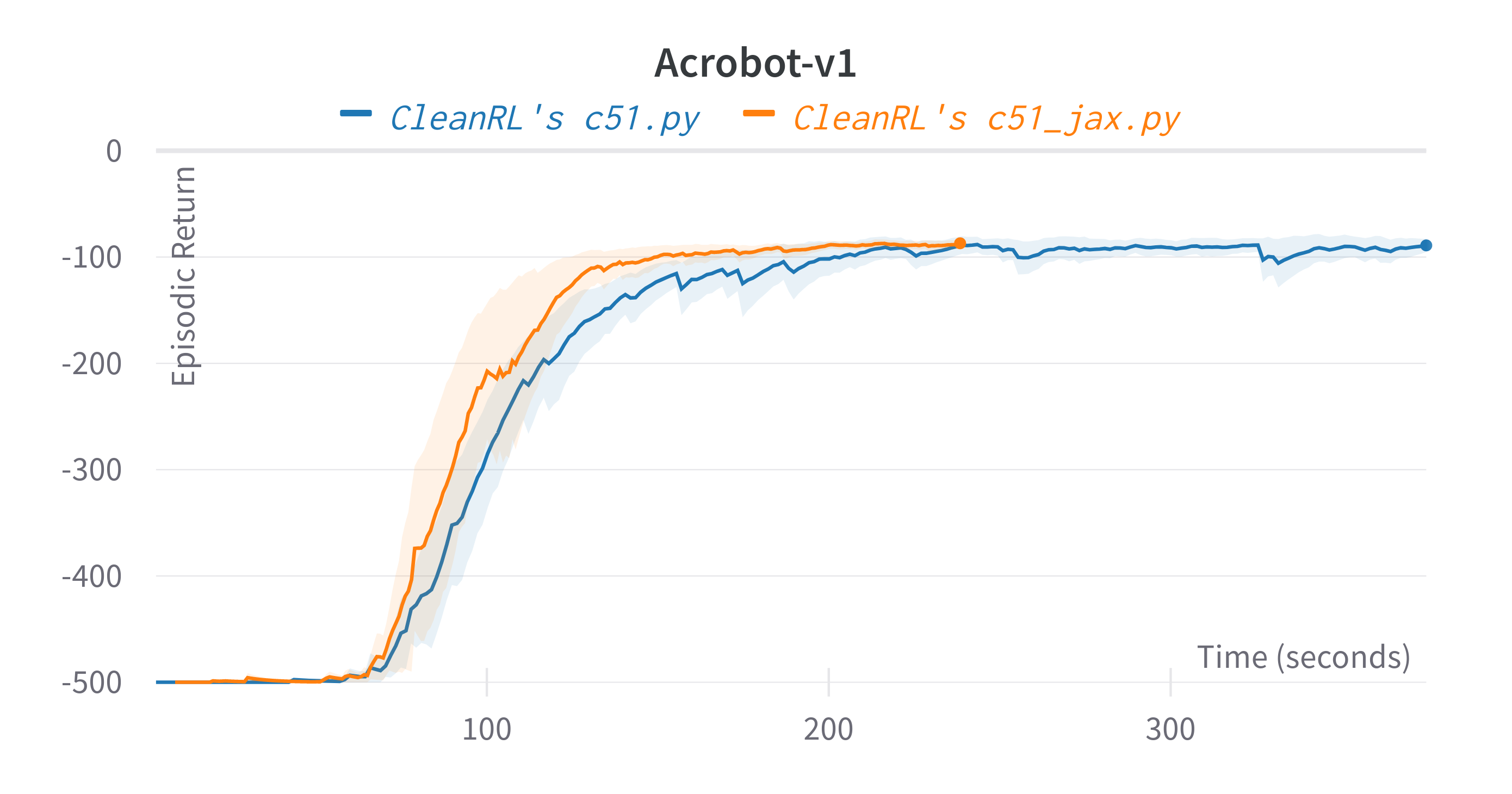
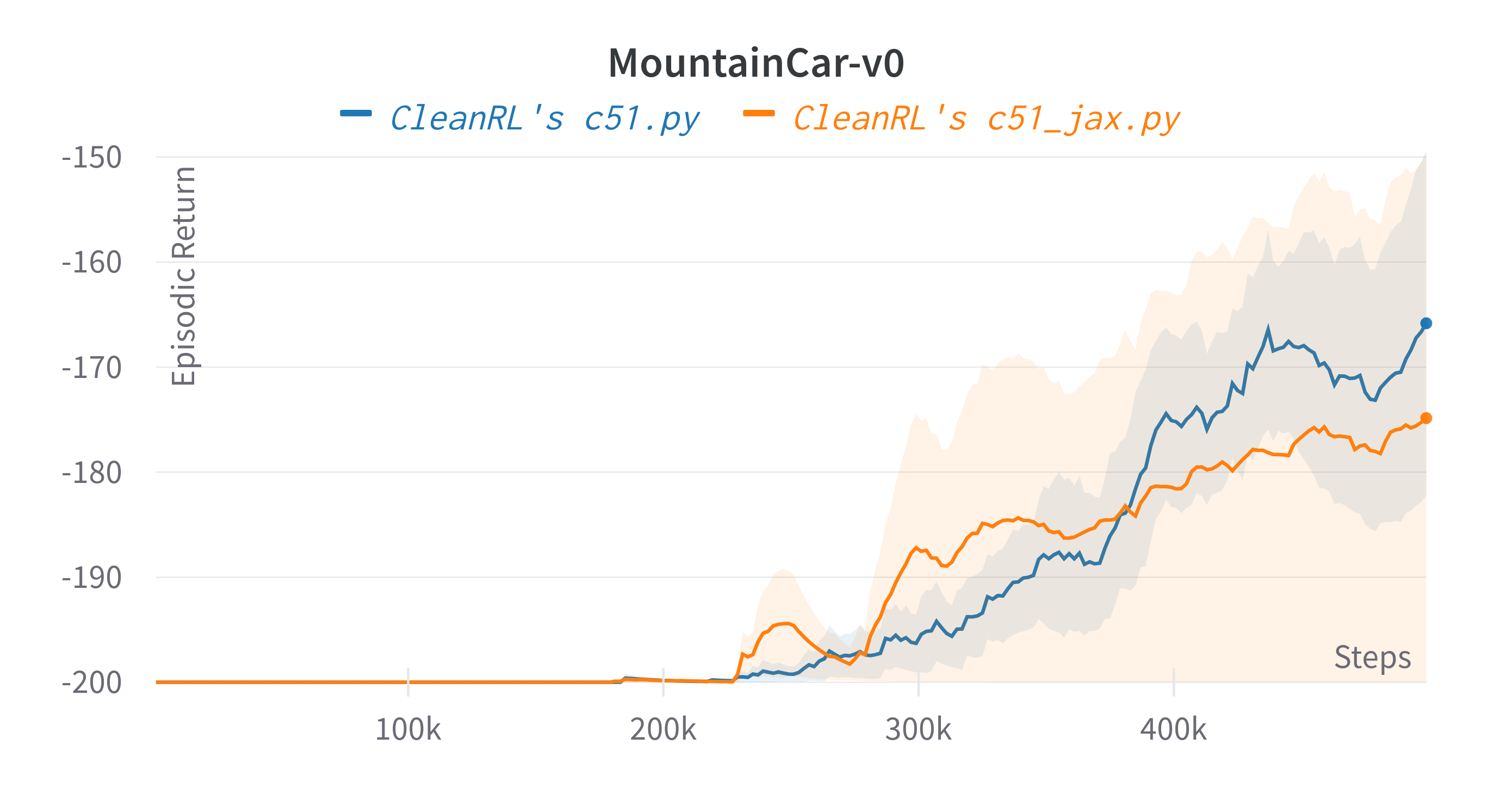
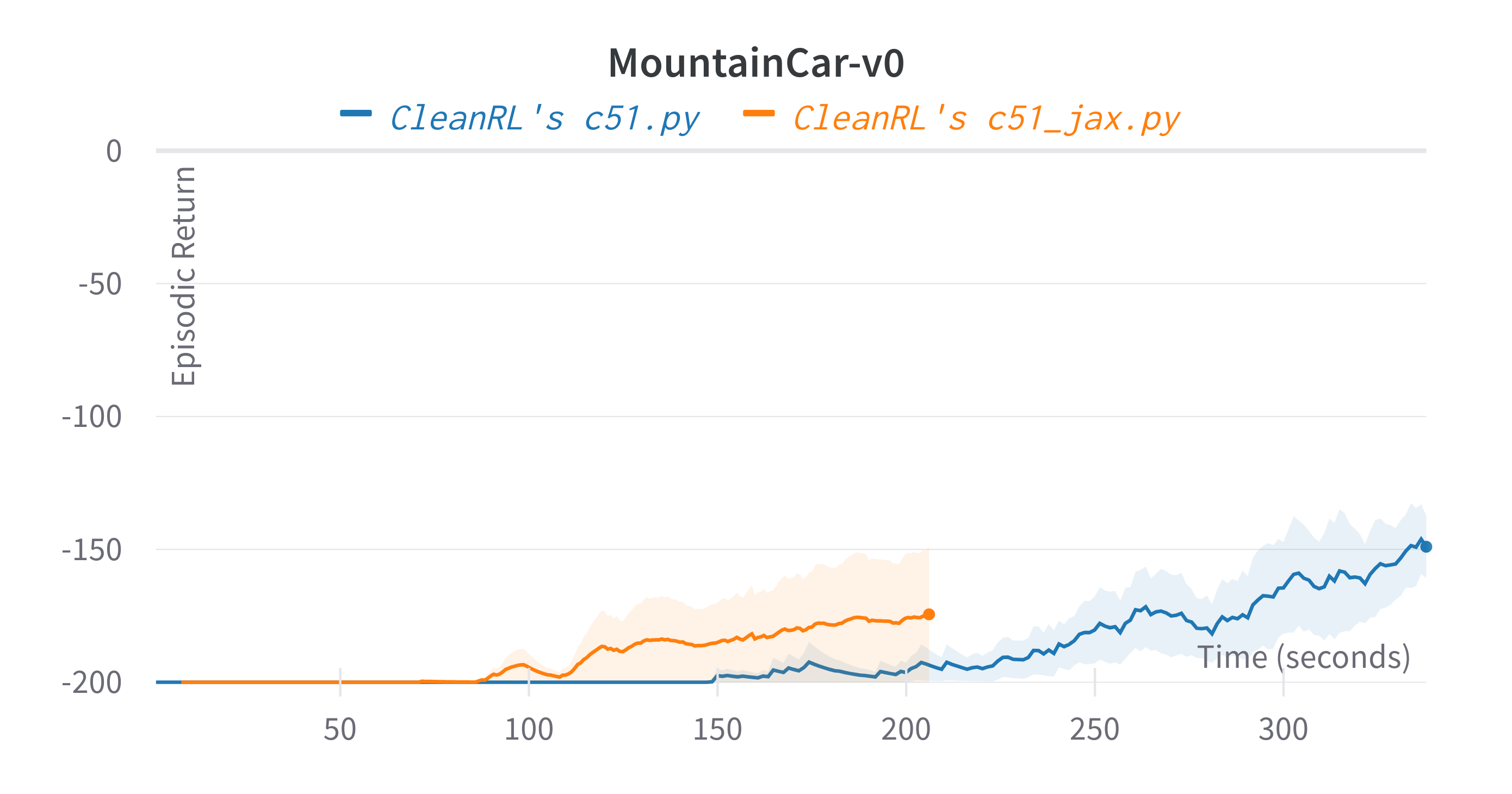
Tracked experiments and game play videos:
-
Bellemare, M.G., Dabney, W., & Munos, R. (2017). A Distributional Perspective on Reinforcement Learning. ICML. ↩↩↩↩↩↩
-
[Proposal] Formal API handling of truncation vs termination. https://github.com/openai/gym/issues/2510 ↩
-
Hessel, M., Modayil, J., Hasselt, H.V., Schaul, T., Ostrovski, G., Dabney, W., Horgan, D., Piot, B., Azar, M.G., & Silver, D. (2018). Rainbow: Combining Improvements in Deep Reinforcement Learning. AAAI. ↩↩